而我看完这篇故障报告以后的最大感受就是:软件工程领域真的没有什么新鲜事,OpenAI 这次遇到的所有问题在无数的公司里都曾经遇到过,就算你是一家估值达到了 1570 亿美金的公司也不例外。不过在详细分析这篇故障报告之前,我想先讲讲「算法」与「工程」的关系。
在很多中型或者大型公司里,「算法科学家」和「软件工程师」似乎是两个泾渭分明的岗位,或许大家已经默认了算法科学家就是一群只会研究算法,对工程一窍不通的「傻子」(或者反之)。这个认知倒不一定没有一点根据,在我过往工作过的公司里的确存在一些对软件工程知之甚少的所谓算法科学家,举个最简单的例子,这些人写的 Python 代码可能连 PEP8 都过不了,一个连代码都写得乱七八糟的人,你又该如何信任他的技术实力呢?很多在软件工程师看来「天经地义」的工程实践,在算法科学家眼里似乎「一文不值」。此时或许会存在「只要算法牛逼就行了」这种极端的论调,但在我浅薄的认知里,我认为:一个优秀的算法科学家,也一定是一个合格的软件工程师。这并不是一个既要又要的苛刻要求,而是因为在一个实际的工程项目中,模型算法必然只是其中一个组成部分,甚至是很小的一部分。如果没有良好的工程实现,你上到生产环境结果推理服务的 QPS 只有个位数有啥意义?你是在浪费 GPU 算力吗?当然在大型项目中肯定也还是需要分工,并不是说所有事情都必须让算法科学家一个人干,但我觉得你得对整个 pipeline 都有了解,否则就真的成了只会「炼丹」的法师了。虽说在大公司工作很容易变成一颗螺丝,但如果连你自己也甘愿做一颗螺丝,那就真的不仅仅是公司的错了。
下面是针对这篇故障报告我的一些具体体会,如果你还没有完整看过强烈建议你先看一遍(就别让 AI 帮你总结了),然后带着你的思考看我后面的内容。
首先所有人最关心的问题我想可能是事故是由什么原因造成的。关于事故原因原文写得很清楚:
As part of a push to improve reliability across the organization, we’ve been working to improve our cluster-wide observability tooling to strengthen visibility into the state of our systems. At 3:12 PM PST, we deployed a new telemetry service to collect detailed Kubernetes control plane metrics.
…
With thousands of nodes performing these operations simultaneously, the Kubernetes API servers became overwhelmed, taking down the Kubernetes control plane in most of our large clusters.
…
In short, the root cause was a new telemetry service configuration that unexpectedly generated massive Kubernetes API load across large clusters, overwhelming the control plane and breaking DNS-based service discovery.
简单讲就是 OpenAI 技术团队为了提升整体系统的可靠性和可观测性,部署了一个新的监控服务到生产环境里,但是意料之外的是这个监控服务使得 K8s 集群里的所有节点发送了大量请求给 K8s API server,导致 K8s API server「过载」,最终造成所有服务不可用。
对于有经验的架构师来说看完这段事故原因必然会产生几个疑问:
- 为什么监控服务作为一个旁路组件会对 K8s API server 产生大量请求?
- K8s API server 有做高可用吗?
- 为什么线上服务要强依赖 K8s API server?
- 为什么要一次性全量上线这个新组件?
上面这几个问题通过这篇报告并不能完全解答(例如前两个问题),但我相信 OpenAI 的工程师一定足够专业,因此 K8s API server 也一定做了高可用部署(可以参考 K8s 官方文档)。但即便 K8s API server 是高可用的,线上服务强依赖它依然是一个「死穴」。线上服务之所以要依赖 K8s API server 其实是为了实现「服务发现」,在我 2015 年写的「关于微服务的一些实践与思考」文章中已经提到过服务发现可以有多种实现方式,在 OpenAI 的架构里他们是通过 DNS 来实现。DNS 这个看起来「去中心化」的实现方式在 K8s 的设计里却依然依赖 API server 作为一个「中心化」的配置中心(本质上是依赖背后的 etcd),相当于把「服务发现」这个非常核心的功能耦合在了一个「单点」上。这里讲的「单点」并不是说 API server 背后的 etcd 无法实现高可用,而是说如果像 OpenAI 这次事故一样出现了无法承载的流量,即便 etcd 是高可用的也无济于事(leader 会挂,follower 也必然挂)。常规意义上的「高可用」都是建立在服务至少还能正常工作的假设下的,如果连服务都无法正常工作了那又何谈高可用?
那该如何处理这种异常情况呢?OpenAI 介绍了他们当时的临时解决方案:
- Scaling down cluster size: Reduced the aggregate Kubernetes API load.
- Blocking network access to Kubernetes admin APIs: Prevented new expensive requests, giving the API servers time to recover.
- Scaling up Kubernetes API servers: Increased available resources to handle pending requests, allowing us to apply the fix.
翻译一下就是:集群缩容(减少 API server 的请求量,降低 API server 负载)、从网络层拦截 API 请求(同样是为了降低 API server 的负载)、给 API server 机器扩容(至少能正常处理一些请求,不至于死得太快)。这几个措施的确是有效果的,也可以说是此次事故处理的关键点,如果没有这样的有效处理,事故持续时间只会更长。但如果回过头来冷静审视,是否有更好的应对措施呢?
「服务过载」是任何一个软件工程师都要面临的问题,大家往往会觉得这个问题可能会更多发生在直接面向外部用户的业务服务中(比如淘宝双 11、12306 抢票、微信春晚红包),因此也就容易忽视「内部服务」也可能面临同样的问题,这次 OpenAI 的事故就很好说明了这一点。很多时候威胁并不来自外部,而是由内部造成的。某些过载是可以提前预防和规划的(比如特定的活动),但往往都无法提前预估。如果真的出现了服务无法承载的流量该如何处理呢?「服务降级」其实是一个实践了很多年的应对措施,服务降级的本质是通过主动「牺牲」一些服务质量,来换取整体系统的可靠,简单讲就是「可以挂,但不能全挂」。
我之前在小红书工作时也在首页的「发现 Feed」服务中有过相关实践。「发现 Feed」是每个小红书用户打开 app 的第一个页面,承载了绝大多数的流量,并且有明显的业务波峰波谷(例如晚上是其中一个业务高峰期)。「发现 Feed」本质上是一个推荐系统,因此这个服务的计算量比普通的业务会大很多,但是为了保证用户体验,服务的响应时间必须控制在几十毫秒到百毫秒这个量级。当业务高峰期时,很容易就因为处理不过来请求而导致请求超时,对于用户来说的体验就是打开小红书首页结果发现「白屏」了。为了应对高峰期的突发流量,受微信后端团队的一篇论文「Overload Control for Scaling WeChat Microservices」启发,我实现了一个根据流量变化动态调整服务质量的框架。你可以简单理解为一个自动化的服务降级框架,当业务高峰期时,如果服务发现自己已经无法承载更多流量,会主动舍弃一些请求,来换取整体服务的可用性。当然舍弃用户请求并不是说给用户看「白屏」,整个「发现 Feed」服务还有多个维度的降级策略,如果无法给用户推荐高质量的内容,那就算返回一些相对「低质量」的内容也是可以接受的,总比整个服务都挂了导致用户啥都看不见强。
因此我也在想 K8s API server 是否可以有类似的自动降级策略呢?当然我并不是 K8s 专家,或许 K8s 社区已经有了好的解决方案。如果 K8s 架构里依赖 API server 这个「单点」在所难免,那就得准备好 API server 随时不可用的预案。
前面我提的第 4 个问题是「为什么要一次性全量上线这个新组件?」,在这篇事故报告的时间线里有提到:
OpenAI operates hundreds of Kubernetes clusters globally.
…
- December 11th, 2024 at 2:23pm: The change to introduce the new service was merged and the deployment pipeline triggered
- 2:51pm to 3:20pm: The change was applied to all clusters
14:23 开始触发 CD,14:51-15:20 完成部署,在短短 30 分钟内就完成了全球数百个 K8s 集群的部署让人不得不赞叹 OpenAI 部署系统的高效。但是我的疑问其实是为什么一开始就要全量上线呢?如果是我来选择的话,我一定不会冒风险一次性全量上线,特别是在涉及全球几百个集群的情况下。这并不是说我「胆子小」,一个系统从来不是靠谁胆子大而变得稳定可靠的。在多年的工作经验中,我发现了一个有趣的现象,就是:软件工程师不论技术高低,都会存在一种「侥幸心理」,会有一种莫名的「自信」认为自己的代码上线以后「应该」没有问题。这种自信的来源可能有很多种,比如觉得自己技术牛逼代码肯定没问题、我已经写了单元测试(并且跑通了!)、我甚至连集成测试都写了、单纯就是懒得测试上线了再说。但是,软件必然存在 bug,也必然存在意外。为了防止意外发生或者尽量减少意外的影响范围,软件工程领域其实已经有了很多最佳实践,比如灰度发布、蓝绿部署、特性开关、A/B 实验。既然前人已经积累了这么多好的实践,为什么不在实际项目中合理运用呢?我实在想不到有什么理由必须在上线第一天就全量生效(尤其考虑到事故的影响范围),很多时候其实都是因为「懒得弄」所以干脆全量上线得了,反正出了事故可以回滚不是?的确,及时发现问题及时回滚也是一种好的实践,但是看看 OpenAI 这次事故遇到的窘境:
Monitoring a deployment and reverting an offending change is generally straightforward, and we have tools to detect and roll back bad deployments. In this case, our detection tools worked and we detected the issue a few minutes before customers started seeing impact. But the fix for this issue required us to remove the offending service. In order to make that fix, we needed to access the Kubernetes control plane – which we could not do due to the increased load to the Kubernetes API servers.
OpenAI 的检测工具甚至在用户发现问题的几分钟前就已经提前预警,但是由于 K8s API server 过载导致连回滚都无法正常进行,陷入了一种「进退两难」的困境。所以,任何时候都不要假设出了问题可以及时回滚。
这里再次分享一个之前在小红书的实践经验。「发现 Feed」服务一开始是一个「大而全」的服务,随着业务变得复杂,什么功能都往里塞,逐渐使得服务的性能和可维护性都面临了挑战。因此和很多公司一样,我们选择把「发现 Feed」服务进行微服务改造,其中我负责的就是把核心的笔记召回服务拆分出来(关于什么是「召回」可以阅读我写的「如何设计与实现一个分布式索引框架(一)」这篇文章)。服务拆分以后带来的好处自然不必说,但是也可能带来一些负面影响,比如响应时间变长、用户体验变差等。在实际上线以前谁都不敢保证最终的效果如何,因此我们选择了把这次架构改造变成一个 A/B 实验来进行。也就是把用户分成两个组,实验组访问新架构的服务,对照组还是访问旧的服务,然后观察这两个组的用户行为指标(比如曝光、点击、互动等)。采用 A/B 实验来上线除了可以对比不同用户的行为以外,另一个好处就是可以灵活控制实验的影响范围。对于这种大的架构改造,我们通常在最开始上线的时候都会比较保守(例如只圈定 1% 的用户加入实验),随着时间推移以及效果评估,会逐步增大用户比例,最终 100% 全量上线。实验过程中新服务可能会发生一些严重故障,此时就可以迅速把实验流量全部切回旧服务。最终这个实验在线上跑了几个月以后新服务才正式替代旧服务,并且实验结果也非常不错,在多个用户行为指标上有显著提升。
随着这几年 AGI 的热潮,技术圈的关注焦点都围绕在了 AI 上,而传统的软件工程技术反而较少提及。诚然,像「Attention is All You Need」这样具有划时代意义的革新一定会载入史册,但就像我在文章开头所说的,一个工程项目绝不仅仅只有模型和算法,还有大量看起来不够「炫酷」、甚至「无聊」的工作需要完成。我相信很多软件工程的最佳实践在 AGI 时代依然存在它的价值,至少目前 AI 还不能取代一个优秀的架构师。看到当下的很多讨论都在说 AGI 时代的到来对于学生未来的学习方向有什么影响,我想说的是不要忽视那些看似「过时」的技术或者所谓的「基本功」,更不要让自己仅仅成为一个「提示词工程师」。
最后是彩蛋时间,我问了 GPT-4o mini 以下问题,从目前的回答来看,只能说我们离 AGI 的距离还挺远的。
「Maybe Tips」是一档以「我不知道对你们是否有用,反正对我来说很有用」为宗旨的栏目,每一期只会围绕一个主题,可能是一个我觉得好用的 app,也可能是某个奇怪的使用技巧。篇幅不求长短,反正写长了也没人看。以下是正文。
![]()
本期介绍的是一个叫做 Input Source Pro 的 app,看作者的 GitHub 主页,应该是一位生活在加拿大的华人。这个 app 是用来干嘛的呢,请允许我先引用一段作者自己写在 app 主页上的话:
作为多输入法用户,我经常会遇到弄混输入法的情况。虽然大部分情况下无关痛痒,但注意力集中时被这种事情打断,多少也有点影响节奏。
以上这段话应该对于所有日常需要处理多语言的人来说都会产生很强烈的共鸣(所以说米国人是肯定不会做出这种 app 的),当我发现这个 app 时只有一种「相见恨晚」的感觉。不知道你有没有遇到过类似的场景,当你想要打字时,本来想打英文,结果敲了几个字母以后发现还在用中文输入法,然后就得先把刚刚敲的那几个字母删掉,切换回英文输入法,最后再开始打字。反过来也是类似的,本来想打中文,结果输入法还是英文,就又得重复一遍刚才描述的过程。如此反复,在我日常的工作和生活中总是会不断面临着这样的困扰。
有些人可能就会说了,你打字之前看一眼右上角的输入法图标不就好了吗?这句话说得很有道理,但人都是很懒的,如果每次打字之前都要先去看一眼输入法状态那就实在太麻烦了。况且在 macOS 上还可能出现把 app 全屏显示的时候,这时顶部的菜单栏都是隐藏的,自然也就没法很方便地查看当前输入法是什么了。
于是我就在想是不是可以把输入法状态显示在离打字的视线更近的地方呢?当我们在打字时什么地方离视线最近呢?对了,光标!有了这么一个灵光一闪的想法以后,我就开始以各种关键词搜索,看看有没有人已经实现了我的这个想法。不得不说,这是一个很小众的需求,经过一番查找我只找到了一个可以把输入法状态显示在鼠标指针(注意不是光标)上的 app,叫做 YouType,作者是一个俄罗斯人。YouType 能做到的是当你把鼠标点击到某个输入框时,会在鼠标指针旁边显示一个国旗的小图标来告诉你当前的输入法是什么。这个操作逻辑其实挺合理的,对于大部分习惯用鼠标的人来说的确会有这样的流程。不过对于我来说,我更习惯于用键盘操作,所以鼠标指针大部分情况下在我的电脑上其实是「隐藏」的,于是为了用这个功能,我不得不时不时晃动一下鼠标来确认当前的输入法状态,这样用起来其实就有点别扭了,最初用这个 app 是希望能帮我减少打字时的负担,现在反而增加了一些负担。所以我又继续去搜寻是否存在这样一个 app 可以完美满足我的需求,这一次我找到了 Input Source Pro。
当我打开 Input Source Pro 主页的那一刻,我就知道它完全就是我想要的,而且这个 app 居然还是免费的!Input Source Pro 的逻辑其实很简单,当你切换输入法的时候会在光标右上角出现一个提示,同时这个提示还可以变成一个「小圆点」持续显示在光标右上角。你可以为不同的输入法设置不同的颜色,这样你就可以仅仅凭借点的颜色来分辨当前的输入法是什么了。举个例子,我把英文输入法设置为了黄色,中文输入法设置为了蓝色,打字时的效果就会像下面这样:

可以看到随着你打字时光标的移动,右上角的小圆点也会跟随移动。并且在切换输入法以后,小圆点的颜色也随之变化。整个 app 的功能完美融入到了你的打字流程中,对用户来说是一个非常自然的体验。细心的人可能注意到了,在切换输入法时除了右上角的提示以外,在光标正下方还有一个提示,只不过下方的这个提示只有一个图标,并没有把输入法的名字显示出来,并且不同输入法的颜色也都是同样的蓝色。这个提示其实并不是 Input Source Pro 的功能,而是 macOS 14(Sonoma)开始引入的新特性。我在 Sonoma 发布之前就已经在使用 Input Source Pro 了,所以当我升级到 Sonoma 发现新的 macOS 居然加入了一个和 Input Source Pro 差不多的功能时还是觉得很惊讶。不过似乎也有一些人并不喜欢 Sonoma 的这个新功能,如果你想把它关掉会稍微有点麻烦(系统设置里并没有提供开关),可以参考这里的讨论。
以上就是我发现 Input Source Pro 之前最想要的功能,不过我还惊喜地发现这个 app 提供了一些额外的有用功能。比如为不同的 app 设置不同的默认输入法,这个功能有什么用呢?我觉得至少对于程序员来说非常有用,因为日常工作中可能需要频繁在终端、代码编辑器、聊天工具等 app 之间进行切换,而不同的 app 会有不同的输入偏好,比如终端和代码编辑器通常就希望用英文输入法,而聊天工具则希望用中文输入法。有了这个功能以后,就可以为不同的 app 设置不同的默认输入法,这样当你从聊天工具切换到终端时输入法也会自动切换,对于懒人来说非常方便。
这个 app 甚至还可以根据浏览器里不同的网站来自动切换输入法,只要写好域名的匹配规则(比如后缀匹配、全匹配、正则表达式匹配),就可以自动切换到你设定的默认输入法。比如把 github.com 这个域名作为匹配规则,那当你每次访问 GitHub 时都会默认使用你设定的输入法。还可以为浏览器的地址栏设定一个默认输入法,对于我来说我会把它设定为英文输入法,我可不想输入网址时还要手动从中文输入法切换回来。
以上就是关于 Input Source Pro 的介绍,我觉得相对于它给我带来的「幸福感」提升,我完全值得为它付费,无奈作者一直没有推出付费计划。不过幸好他有开通 GitHub Sponsors,如果你觉得这个 app 有帮到你,也欢迎去给作者打赏。
]]>「Maybe Tips」是一档以「我不知道对你们是否有用,反正对我来说很有用」为宗旨的栏目,每一期只会围绕一个主题,可能是一个我觉得好用的 app,也可能是某个奇怪的使用技巧。篇幅不求长短,反正写长了也没人看。以下是正文。
![]()
本期介绍的是一个叫做 One Thing 的 app,知道这个 app 其实是因为先了解到了同一个作者的另一个 app——Hyperduck(一个可以从 iOS 共享信息给 macOS 的工具,有点类似于 AirDrop 和 Handoff,不过我最终并没有用 Hyperduck,我还是更习惯于原生的功能)。这个作者厉害的地方在于他独立开发了非常多的 app,你可以去他的主页查看,而 One Thing 就是其中一个。
之所以要介绍 One Thing 是因为它解决了一个长久困扰我的问题。话说从头,基于众所周知的原因,在中国大陆访问互联网除了需要梯子以外,还有一件非常重要的事情就是「DNS 服务器」。并不是说你需要自己部署一个 DNS 服务器,而是需要使用那些没有被「污染」过、可信任的 DNS 服务器。所以我在日常的网上冲浪过程中会特别关注当前使用的 DNS 服务器是什么,因为你的电脑可能会由于各种奇怪的原因重置回默认的 DNS 服务器。为了快速查看和切换到正确的 DNS 服务器,我使用了 Alfred 的 atop workflow。这个 workflow 大大简化了确认和设置 DNS 服务器的流程,不过我还是觉得每天反复 N 次去人肉检查是一个很蠢的行为,基于职业习惯我希望把整个流程变成一个自动化的操作(比如定期把当前的 DNS 服务器显示在右上角的菜单栏里)。经过一番网络搜索,我并没有找到这样一个可以解决我问题的 app 或者方法,于是只能继续人肉检查。直到有一天我发现了 One Thing 这个 app。
One Thing 的功能其实非常简单,它有且只有一个功能,就是在右上角的菜单栏里显示一个你自定义的内容。也许你会想这个功能和前面提到的 DNS 服务器有什么关联吗,不要着急,One Thing 强大的地方不在于此,而在于它可以和 Shortcuts(快捷指令)集成!感谢阿库,让我们可以在 macOS 上使用 Shortcuts,一旦某个应用支持了 Shortcuts,那它就有了丰富的使用场景。于是我要做的事情就非常简单了,你可以点击这里查看我制作的 shortcut(截图如下)。这个 shortcut 其实只有两个步骤,首先使用脚本获取当前的 DNS 服务器,然后通过 One Thing 把这个服务器显示在菜单栏里,大功告成!
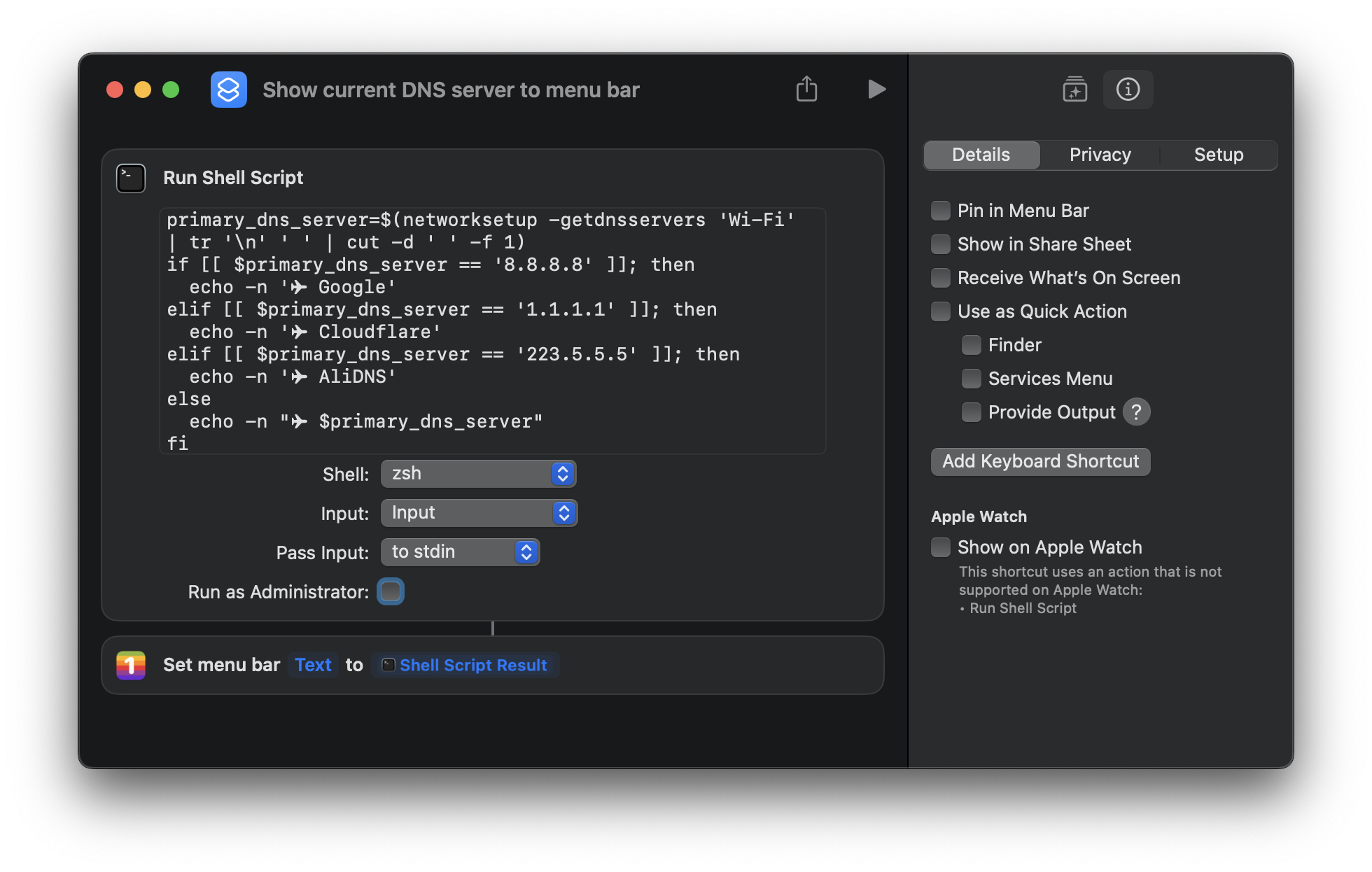
不过还有一件事情没有实现,shortcut 通常都是由人来手动触发执行的,但是我的需求是定期执行 shortcut,这个功能在原生的 macOS 里并不支持,于是需要借助一些第三方的工具来完成。在 One Thing 官网里推荐的是 Shortery(如果想要基于时间触发执行 shortcut 需要花 $9.99 升级为 PRO 版本),而我用的是已经使用了很多年的 BetterTouchTool。不管你用哪个工具,最终效果都差不多,只要能基于时间定期执行 shortcut 就行。
至此所有需求就已经都满足了,从想到这个点子到最终实现出来其实花不了太多时间,很多时候可能只是因为缺少了某些关键信息而不能往前推进。如果我没有因为看到 Hyperduck 而恰好发现 One Thing 的话,我估计我还得每天重复着相同的检查工作。
]]>年度 Top 5 电影
宇宙探索编辑部(Journey to the West,2023)

最早知道这部电影是在机核里看到了它的预告片,预告片里那浓浓的 80 年代画风和对白立马击中了我。如果你平日里是一个生活里的恶趣味爱好者,一个喜欢钻研一些看起来无用东西的人,亦或是一个经历过 80 年代的人,或者恰巧是「跟宇宙结婚」节目的忠实听户,那我强烈推荐你看看这部电影。
这部电影属于伪纪录片风格,导演孔大山 2015 年的另一部作品《法制未来时》可能更加为人所知,这是一个不到 10 分钟的短片,你可以通过这个片子提前感受一下导演的风格。
导演已经在很多场合公开表示过电影参考了《西游记》的人物关系和剧情内核,电影的英文名《Journey to the West》其实也提示得相当明显了。虽然是一部伪纪录片风格电影,但加上《西游记》的故事内核,让这部电影又有了一些公路片的味道。我们着迷于主人公唐志军追寻「答案」的过程,希望这个故事永远不要结束,但是电影毕竟需要一个结尾,不管你是否喜欢,电影都需要让主人公找到他心目中的那个答案。在表面看似荒诞的剧情中,《宇宙探索编辑部》给我带来的感受更多是一种与当今时代格格不入的凄凉,或许每个时代都有这样的事情在不断重演,这注定是属于一小部分人的宿命。
除了饰演唐志军的杨皓宇以外,令我印象深刻的还有饰演那日苏的蒋奇明,刚好我是先看的《漫长的季节》,因此对于能在这部电影中看到蒋奇明感觉甚是惊喜。
最后如果你对这部电影的一些幕后故事感兴趣,推荐你听一下「散场通道」播客对导演孔大山的一次访谈(点击这里收听)。
河边的错误(Only the River Flows,2023)

这部电影和《宇宙探索编辑部》还有些渊源,两部电影都参加过「平遥国际电影展」,也都获得了当年的「费穆荣誉最佳影片」,只不过《宇宙探索编辑部》是 2021 年获的奖,而《河边的错误》是 2023 年。
《河边的错误》改编自余华的同名小说,由于电影完全采用 16mm 胶片拍摄,因此在网上会看到类似「画面模糊、虚焦」的差评,但我在观看的过程中倒没有这方面的困扰,可能是由于我不是在大银幕观看的原因。
这部电影或许很容易被归类为「文艺片」,在影片气质上的确也有很浓烈的艺术片风格,特别是后半段对于主人公梦境的一些意识流表现。但是这部电影又不像很多传统文艺片那样没有明显的主线剧情,从影片开始到结尾其实都贯穿了一个悬疑案件,作为刑警队队长的主人公也在一步步带着观众去探寻「真相」。但我觉得「悬疑」并不是这部电影想要表达的核心(或者可能余华的原著也是如此?),更多是想展现大时代背景下不同人物的困境,某种意义上这部电影更像一个群像戏,「悬疑」只是吸引观众往下观看的一个引子。所以按照这样的理解,那其实所谓的「案件真相」也就变得不那么重要了。如此看来,《漫长的季节》其实也是这种类型的影片,只不过《河边的错误》的表达更加隐晦,这可能也是电影和剧集的区别。
最后如果你对这部电影的一些幕后故事感兴趣,推荐你听一下「散场通道」播客对本片摄影指导程马的一次访谈(点击这里收听)。听完这个访谈以后最让我震惊的不是胶片拍摄有多难,而是本片在后期剪辑时几乎一刀没剪,这可能也是一种实力的体现吧。另外本片导演魏书钧 2021 年的另一部电影《永安镇故事集》我其实也挺感兴趣,无奈暂时没有资源和渠道可以观看。
东方快车谋杀案(オリエント急行殺人事件,2015)

看电影名你可能已经猜到了,这部影片正是根据阿加莎・克里斯蒂著名的同名小说改编。和《河边的错误》这种「假悬疑片」不同,阿加莎的故事是一定不能被提前剧透的!因此如果你还没有看过这个故事,强烈推荐你先看看其它版本的《东方快车谋杀案》(或者直接看小说)。这部小说已经被多次改编成了电影,我最早看的是 1974 版,虽然看年代感觉会是一个很老的片子,但其实 1974 版可能是最好看的版本,导演是著名的西德尼・吕美特(代表作包括《十二怒汉》、《热天午后》)。
回到这部日本版《东方快车谋杀案》,和之前欧美国家拍摄的版本有什么区别呢?表面上最大的区别肯定是演员从欧美人换成了亚洲人,但这部影片的编剧「三谷幸喜」才是促使我有兴趣观看的原因。三谷幸喜是日本著名的编剧和导演,他的影片通常会归类为喜剧,但喜剧可能也只是他进行自我表达的一个外壳。如果你从来没有看过三谷幸喜的作品,那我推荐你先看看他的几个代表作品,比如《有顶天酒店》、《广播时间》、《魔幻时刻》、《大空港 2013》、《笑之大学》。
这部三谷幸喜改编版的《东方快车谋杀案》分为上下两部分(影片里称为「第一夜」和「第二夜」),上部是对阿加莎・克里斯蒂小说的完美还原,只不过故事和人物设定换成了更符合日本时代背景的风格,而下部则是三谷幸喜完全原创的内容,这也是为什么即使我已经知道了案件真相也能继续津津有味观看的原因。这部影片肯定算不上三谷幸喜最好的作品,但对于喜欢他的故事风格的观众来说会是一个看完以后足够满足的诚意之作。
惠子,凝视(ケイコ 目を澄ませて,2022)

这是一个属于普通人的平凡故事,没有大开大合,没有强烈的剧情反转,有的只是对于生活的平实描绘。虽然以女性为主角难免会被贴上「女性主义」的标签,但我觉得这部影片对于所有性别的人来说都能获得一些感悟。
影片的设定其实很简单,女主角是一个很喜欢拳击的聋哑人,而故事则围绕着她平常训练的拳馆徐徐展开。可能看到拳击会让人误以为这是一个体育题材的热血励志电影,但事实上这并不是一部讲述一个小人物如何成长并一步一步蜕变的「老套」剧情。反倒对我来说,这是一部温情的电影,女主角虽然不能通过言语表达,这反而让观众更加注意观察她的一举一动,进而体会到那些不经意间流露出的细腻情感。不刻意煽情是我觉得这部影片的优点,很多时候这种「不刻意」会比强行说教带给观众的感受更加强烈。
如果你对这部影片感兴趣,推荐你在一个安静的时刻和环境里观看。
花束般的恋爱(花束みたいな恋をした,2021)

其实很早就在豆瓣上标记了这部电影,但直到 2023 年才看与下面要推荐的「年度 Top 5 剧集」里的其中一部有关。演员阵容很强大,菅田将晖、有村架纯、小田切让、户田惠子、小林薰,甚至押井守都来客串了一把。编剧是著名的日剧编剧坂元裕二(代表作《东京爱情故事》、《最完美的离婚》、《四重奏》),而配乐是著名的音乐家大友良英。
我会把某一类爱情电影归类为「纯爱电影」,看完这类电影以后会让人产生强烈的「恋爱真美好」的感觉,而《花束般的恋爱》正是这样的电影,很多年前看的《和莎莫的 500 天》其实也属于这类电影。但相比《和莎莫的 500 天》,《花束般的恋爱》显然要更残酷一些。恋爱里有的不只是两个人轻松愉快在一起的时光,还有更多恋人们在恋爱之前根本不会考虑的事情发生。恋爱到婚姻是一个漫长的过程,可能年轻时还会把这两个概念等同,但随着年龄增长会逐渐认识到二者之间存在着巨大的鸿沟,只有成功跨越鸿沟的恋人才能长相厮守。
但无论如何,不管你的年纪多大,不管你是单身还是已经成家,我都推荐你看看这部电影,毕竟每个人的内心都一定怀有那份美好。
如果你喜欢看纯爱类型的影片,那我还推荐你看看 2022 年满岛光主演的日剧《初恋》。为了减少重复的题材,这部剧没有进入我的「年度 Top 5 剧集」,但依然非常推荐。
年度 Top 5 剧集
短剧开始啦(コントが始まる,2021)

这是我 2023 年唯一一部在豆瓣上打了 5 星的剧集,即使已经看完过了很久,现在想来这部剧带给我的也还是很多的感动。
这部剧我是在叶子的推荐下才入的坑,剧集围绕 3 个梦想从事短剧行业的年轻人展开,每一集都是基于 1 个他们的短剧开始,然后讲述很多短剧背后的人物故事,这里面有友情,有爱情,有亲情。虽然看起来似乎是有点「老套」的日式剧情,但就像《惠子,凝视》的「不刻意煽情」一样,这部剧集也不是说教式地给观众灌输情绪,编剧以一种很巧妙的方式讲述了一个个故事,直到最后一集以一种反高潮但同时又带有希望的设定结束。
前面也提到了,我也是因为看了这部剧集里菅田将晖和有村架纯的表演,才产生了去看《花束般的恋爱》的想法。仲野太贺在这部剧集的表演也让人印象深刻(我最早是通过《我是大哥大》认识他的)。
火线(The Wire,2002-2008)

这部剧完全是在听了重轻在机核的节目「《火线》导读」以后才去看的,这个剧集总共有 5 季,一口气补完需要不少时间,但好歹还是看完了。对我来说,5 季里并不是每一季都很精彩,不过总得来说《火线》是一部不容错过的作品。
《火线》的故事设定在美国的巴尔的摩(Baltimore),这个城市毒品盛行,白人和黑人的冲突不断,以抓捕头号毒贩为目标而临时组成的调查组把几个主角聚在了一起,故事由此而展开。当然等你看完整个 5 季以后会发现《火线》想要讲述的不仅仅是警察抓捕毒贩这么简单(如果你想看这类型的剧集,我更推荐看《毒枭》),它更多反映的是巴尔的摩这个城市,从富人到贫民,从政客到警察,从码头工人到法官,从学生到老师,从毒虫到毒贩,从街头侠客到新闻记者,所有人共同组成了巴尔的摩。在我看来,编剧大卫・西蒙(David Simon)作为一个在《巴尔的摩太阳报》工作了 12 年的记者,他的野心是想要借着缉毒这条线索,为观众完整展现他眼中的巴尔的摩。
可能正是由于大卫・西蒙的这个野心,《火线》与常规的美剧或者警匪片相当不同,没有紧张刺激的剧情,也不会故意制造悬念从而吸引观众一集一集往下看。对于习惯了普通美剧节奏的人来说,《火线》甚至会有点沉闷,你可能要看到第一季后半段才会开始对这个剧集感兴趣,这或许也是为什么《火线》第一季在豆瓣上虽然有着 9.4 的高分,但是只有不到 3 万人评价的原因(相比之下《权利的游戏》第一季有超过 40 万人评价)。
重启人生(ブラッシュアップライフ,2023)

《重启人生》可能是 2023 年最出圈的日剧,没有之一(在豆瓣上有接近 28 万人评价,和《半泽直树》差不多)。对于日剧老粉来说,这部剧里可以看到很多熟面孔,而对于新粉来说在如此强大的演员阵容下也能看个热闹。
故事剧情应该也不用我做太多介绍了,说几个让我印象深刻和有趣的点(注意涉及关键剧透,介意请勿看):
点击查看
- 每次在 KTV 里都会唱《粉雪》这首歌,一秒让我回到高中时看《1 公升的泪》的时光。
- 当小学时期的麻美和真里在轮回中重逢时,两人互相用手势对了个暗号,这段剧情堪称全片高能。
- 三浦透子饰演的河口美奈子在前期穿的卫衣上不仅写着「Go to hell」,下面还有几行小字「To tell the truth, I’m coming back to life many many times」。第一遍看的时候完全没有注意到,后来看剧照才发现这个属于提前剧透的彩蛋。
- 后期河口美奈子卫衣上的文字换成了「Go to Hometown」以及「After all, I love this city the most, not to mention my friends」,可以说是明确点题了。
- 麻美在电视台工作时当舞台的灯光替身,胸前的牌子上写的是「新垣」,应该是当新垣结衣的替身。
- 饰演三田先生的铃木浩介在《短剧开始啦》中也饰演了一个老师
- 夏帆、臼田麻美、山田真步、佐藤玲同时也出演过编剧笨蛋节奏的另一部日剧《架空 OL 日记》
除了正片之外,还有 1 个 9 集的《重启人生 番外篇》,每一集讲述了 1 个配角的小故事,也很值得观看。
最后生还者(The Last of Us,2023)

《最后生还者》最初是顽皮狗(Naughty Dog)工作室 2013 年在 PlayStation 3(PS 3)平台上独占发行的游戏,后来相继发布了 PS 4 和 PS 5 平台的重制版。2020 年在 PS 4 平台上发布了第一代的续作《最后生还者 Part II》,PS 5 重制版也即将在今年 1 月发布。
如果要评选 PS 平台独占游戏的前三名,那《最后生还者》肯定会有一个位置,这也是我在 PS 4 平台接触的第二个游戏(第一个是《神秘海域》,同样来自顽皮狗工作室)。虽然这是一个动作冒险游戏,但最吸引我的还是整个游戏的故事设定,因此《最后生还者》是一个一定不能被剧透的游戏(所以如果你先看了剧集可能会影响游戏的游玩体验)。
2020 年 HBO 宣布将游戏改编成剧集,由《最后生还者》游戏的编剧尼尔・德拉柯曼(Neil Druckmann)和《切尔诺贝利》剧集的编剧克雷格・麦辛(Craig Mazin)共同担任编剧。作为游戏里最重要的两个角色乔尔(Joel)和艾莉(Ellie),在公布扮演者是佩德罗・帕斯卡(Pedro Pascal)和贝拉・拉姆齐(Bella Ramsey)以后,作为游戏玩家其实是相当失望的。虽然我很喜欢佩德罗在《毒枭》中的表演,但还是觉得这两位演员和游戏里的人物气质差得比较远,特别是艾莉的扮演者贝拉・拉姆齐,真的是一点都不像。而且基于过往的经验,游戏改编的影视通常都会扑街,所以对于这个剧集其实也没有抱太大期待,只希望能尽量还原游戏就够了。
然而等到剧集上线第一集以后,看完这集的我只能称赞 HBO 万岁。剧集对于游戏场景的还原度只能用逼真来形容,而之前最失望的选角在看完演员的表演以后不得不说「真香」。作为游戏玩家的彩蛋之一,之前在游戏中作为几个主要角色动作捕捉和配音的演员也参与了剧集的拍摄,例如乔尔和艾莉在游戏中的演员特罗伊・贝克(Troy Baker)和艾什莉・约翰逊(Ashley Johnson)在剧集中分别客串了两个角色。而游戏中的配乐也同样作为了剧集的配乐,当听到片头曲时一定会让每一个玩家兴奋不已。
目前 HBO 已经续订了第二季,由于第一季已经把《最后生还者 Part I》游戏的故事讲完,所以第二季应该会拍摄《最后生还者 Part II》的剧情,剧集预计会在 2025 年上线。
不能结婚的男人(結婚できない男,2006)

正如这部剧的剧名,剧集讲述了一个不想结婚(甚至是痛斥婚姻),一心沉迷于工作和自我世界的大龄单身男性的故事。男主角由阿部宽饰演,由于我在看这部剧之前刚刚看过同样由阿部宽主演的另一部日剧《龙樱》,在这两部剧里两个角色的风格形成了强烈反差,让人印象深刻。
看这部剧时,总是让我想起另一部日剧《最完美的离婚》。一个是不想结婚,一个是最终离婚,两部剧中以男性视角展现出的对于恋爱、婚姻的看法有些许共通之处。当然或许会有人觉得阿部宽饰演的这个男主角有些极端,在现实生活中不太可能出现,但我觉得编剧可能恰恰想在 2006 年这个时间点反映一些日本社会的现状。在一个已经高度发展的社会里,年轻人可能反而没有动力像父辈那样奋斗和前进,没有结婚的欲望,即使结婚了也不想生小孩,这才造成了日本的「少子化」现象,新生儿数也在逐年下降。这个话题其实放到当下的中国也是非常适合的。
就像《龙樱》在上线 16 年后推出了《龙樱 2》一样,这部剧也在上线 13 年时推出了续作《还是不能结婚的男人》。续作还是同样的编剧,同样的导演,同样的男主角,不过女主角们已经换成了新的演员。对于喜欢看第一部的剧迷来说,这个续作也是值得观看的。就我个人而言,我还是更喜欢第一部的演员们,特别是夏川结衣,虽然在这部剧中她和阿部宽最终没有组建家庭,但是在是枝裕和的《步履不停》里两人还是顺利成为了银幕伴侣,算是对粉丝的某种慰藉吧。
年度 Top 5 纪录片
2023 年我也看了不少纪录片,有一段时间还特地找了不少 Netflix 的纪录片来看,我觉得很多时候真实影像的力量相比虚构故事可能会大很多。由于纪录片和虚构影视的差别,所以这里单独列举了一些我觉得值得观看的纪录片。
日本之耻(Japan's Secret Shame,2018)

这是一部所有人都应该看的纪录片,我知道很多人可能会给这部纪录片贴上「女权」的标签,但在我看来事件主角伊藤诗织只是在追求一个人的基本权利,这也绝对不是只有日本社会才有的问题,我相信类似伊藤诗织的故事会不断在全世界发生,任何性别的人都可能承受和她一样的痛苦,仅仅是因为她敢于站出来发声而已。虽然有某种观点是一个好的纪录片不应该带有明显的倾向,但在看这部纪录片的过程中我几乎不可能做到共情「施害者」。
从 2017 年 9 月提起民事诉讼,到 2022 年 7 月最高法院最终判决伊藤诗织胜诉,将近 5 年的诉讼期,伊藤诗织战斗到了最后,也获得了应有的公正,但是对于施害者山口敬之的惩罚仅仅是赔偿 332 万日元(约 16 万人民币)而已,不得不让人叹息。更加讽刺的是,山口敬之也提起了一系列针对诽谤他个人名誉的诉讼,他还因此获得了 189 万日元(约 94000 元人民币)的赔偿。
因为这部纪录片,我又去看了伊藤诗织的著作《黑箱:日本之耻》。相比纪录片,书籍包含了更多的信息,还意外发现伊藤诗织和日本著名记者清水洁其实也有过接触。我是通过《桶川跟踪狂杀人事件》和《足利女童连续失踪事件》这两本书了解到了清水洁其人,对于像他这样的良心记者只能报以莫大的敬意,强烈推荐阅读。
环法自行车赛:逆风飞驰(Tour de France: Unchained,2023)

这是叶子推荐看的纪录片,记录了 2022 年环法自行车赛中几支车队的故事。对于以前只在 CCTV-5 的体育新闻里听说过环法自行车赛的我来说,这项运动只能用陌生来形容,根本不知道比赛规则,也一个车手都不认识。但就像所有体育竞技一样,总是能给人带来振奋和激励,即使是门外汉的我也能看得血脉偾张。这时候比赛规则似乎就显得不那么重要了,透过屏幕观看的我似乎也已经置身法国的小镇或者山谷间,为每一个选手呐喊助威,甚至让我产生了以后一定要去现场看一次的愿望。
看完这个纪录片的时间是 2023 年 7 月 21 日,而 7 月 23 日恰好是 2023 年环法自行车赛的最后一个赛段,意犹未尽的我们继续观看了最后两个赛段(20 和 21 赛段)的直播。最让我印象深刻的并不是头号种子们的较量,而是第 20 赛段法国人蒂博・皮诺(Thibaut Pinot)在他退役前的最后一次环法比赛中拼尽全力,当他往山顶攀登时路两旁的家乡人民那山呼海啸般的喝彩,皮诺就像《出埃及记》里的摩西分开红海一样,用他的奋力前进开启了一条通往山顶的道路。此时的我们已经几乎热泪盈眶,也许这就是体育的精神吧。
攀登梅鲁峰(Meru,2015)

世界上最高的山峰是什么?大家肯定都知道是珠穆朗玛峰(Mount Everest,也叫圣母峰),海拔 8848 米,无数人心目中此生一定要去征服的山峰。那如果问世界上最难攀登的山峰是什么呢?作为攀岩以及登山的门外汉,我一直也以为是珠峰,直到看了这部纪录片。
梅鲁峰(Meru Peak)和珠峰一样,也属于喜马拉雅山脉,位于印度北部。光看海拔,梅鲁峰其实不算高,最高处(南峰)只有 6660 米。但它的中央山峰(海拔 6310 米)被认为是喜马拉雅山脉中可能最难攀登的山峰,特别是那段被登山者称为「鲨鱼鳍(Shark’s Fin)」的路线。而这个纪录片就是对人类历史上首次成功攀登梅鲁峰中央山峰的完整记录。
成功登顶的 3 个人:康拉德・安克(Conrad Anker)、金国威(Jimmy Chin)、雷纳・奥斯托克(Renan Ozturk),都是职业的登山家。其中金国威可能在影迷中最为人熟知,他是 2019 年奥斯卡最佳纪录长片《徒手攀岩(Free Solo)》的导演之一,另一个导演伊丽莎白・柴・瓦沙瑞莉(Elizabeth Chai Vasarhelyi)是他的太太,他俩共同执导了不少热门纪录片,而本片《攀登梅鲁峰》也是一部夫妻共同合作的作品。当然金国威在本片中的身份也比以往他拍摄的影片更为特殊,他不仅要承担记录整个过程的任务,更为重要的他是登山小队中的一员。
攀登梅鲁峰的过程艰险而变幻莫测,这种被称为「阿尔卑斯式(alpine style)」的登山方式显著区别于更为大众熟知的「探险式(expedition style)」,后者对于攀登者的专业要求要小很多,更多是对体力和耐力的考验,典型的代表就是攀登珠峰。「阿尔卑斯式」需要攀登者自己携带所有装备,路线上没有固定的绳索和营地,并且需要精通各种攀岩、攀冰技术。金国威曾在采访中说 99.9999% 的人在看完这部纪录片以后估计都不会想要尝试亲自攀登梅鲁峰,只有极小比例、真正硬核的登山者才会有兴趣。
如果你看完这部纪录片仍然意犹未尽,那我推荐你再去看看《徒手攀岩》(如果你还没看过的话),以及由康拉德・安克主演、金国威参与拍摄的另一部纪录片《最狂野的梦想:征服珠峰(The Wildest Dream)》。
另一个有趣的话题是,Meru 还可以被翻译为「须弥山」,而须弥山是佛教、印度教、耆那教中最高的神山,代表宇宙的中心。
启动:Xbox 的故事(Power On: The Story of Xbox,2021)

这是一个在第一代 Xbox 发布 20 周年之际,介绍 Xbox 如何诞生,并一步一步发展的纪录剧集。总共 6 集,每 1 集都有一个相对独立的主题。前 3 集都聚焦在第一代 Xbox 的诞生故事,第 4 集聚焦在《光环(Halo)》和 Xbox 360,第 5 集聚焦在 Xbox 360 主机著名的「死亡红环(Red Ring of Death)」事件(国内玩家社区俗称「三红」),第 6 集除了自嘲失败的第三代主机 Xbox One 以外,就基本是对现在微软游戏部门 CEO 菲尔・斯宾塞(Phil Spencer)的赞誉。
对我个人而言前 3 集是最有趣的,谁也没想到促使 Xbox 诞生的起点是索尼的 PlayStation 2。1999 年当索尼公开宣布 PS 2 主机时,市场宣传的定位已经从单纯的游戏主机变成了每个家庭必备的娱乐中枢,似乎有了 PS 2 以后人们的娱乐生活就不再依赖 PC 了,而 PS 2 的这个定位已经开始对微软的核心市场造成威胁。
但 Xbox 并不是一个自上而下由领导驱动的项目,反而由 4 个来自 DirectX 团队,在公司内名不见经传的工程师发起。DirectX 是 Windows 平台的多媒体 API 集合(主要是游戏相关),帮助开发者屏蔽底层硬件,以一种统一标准的接口快速开发游戏。DirectX 项目最初其实也是由 3 个工程师发起,早期的项目代号是「曼哈顿计划(Manhattan Project)」,他们用这个二战时的同名项目来展示想要用 PC 游戏取代以日本公司为代表的主机游戏的野心。而 Xbox 项目的 4 个发起者似乎继承了 DirectX 团队「叛逆」的基因,选择迎难而上,挑战横梗在微软公司内部的各个阻碍,并最终说服了比尔・盖茨和史蒂夫・鲍尔默启动这个投入巨大,但关乎微软公司未来的项目。
对于游戏玩家来说,还可以从这个纪录片中获取到一些当年的行业趣闻。比如最初微软并不想自己制造硬件,毕竟软件才是他们的强项,因此他们四处寻找硬件厂商合作但都被拒绝,最后甚至还想通过收购任天堂来达成目标,结果可想而知,任天堂坚定否决了微软的这个提议。因此微软被迫选择自己制造 Xbox 的硬件。
阿波罗 11 号(Apollo 11,2019)

1969 年 7 月 21 日 02:56(UTC 时间),美国宇航员尼尔・阿姆斯特朗(Neil Armstrong)成为首个登陆月球的人类,这对于美国政府的「阿波罗计划(Apollo program)」来说是一个历史性的时刻,也成功兑现了约翰・F・肯尼迪(John F. Kennedy)1961 年在国会上做出的承诺。从阿姆斯特朗执行的阿波罗 11 号任务开始,随后的 5 次阿波罗任务也都成功将宇航员送上了月球。到 1972 年阿波罗计划终止,整个计划一共有 12 名宇航员在月球上行走,而这也是人类历史上至今为止仅有的登月人数。
2019 年是阿波罗 11 号任务的 50 周年纪念,在 NASA 和美国国家档案馆的帮助下,导演托德・道格拉斯・米勒(Todd Douglas Miller)发现了长期被遗忘的记录阿波罗 11 号任务的 70mm 胶片,以及超过 11000 小时从模拟录音转换过来的数字音频。就像发现沉睡多年的宝藏一样,米勒和他的团队将这些胶片全部数字化,对音频进行修复,将视频和音频同步,并最终剪辑成了这个时长 93 分钟的纪录片。米勒将所有观众带回到了 1969 年,以亲历者的视角重新经历了这段伟大的历史。
阿波罗计划终止的 45 年后,2017 年美国政府再次联合欧洲航天局、德国航空航天中心、日本航天局等 6 家机构,发起了新的登月计划「阿尔忒弥斯计划(Artemis program)」。如果一切顺利,人类将在 2025 年再次登月,或许这将开启人类探索太空的下一个篇章。
延伸观看:2022 年的纪录片《回到太空(Return to Space)》,导演是《攀登梅鲁峰》的金国威夫妇,讲述了 SpaceX 公司的一些故事,而 SpaceX 的星舰(Starship)是阿尔忒弥斯计划的重要组成部分。
参考资料
- 《最后生还者》
- 《日本之耻》
- 《环法自行车赛:逆风飞驰》
- 《攀登梅鲁峰》
- Wikipedia: Mount Everest
- Wikipedia: Meru Peak
- Wikipedia: Alpine climbing
- Wikipedia: Mount Meru
- The Outdoor Journal: Himalaya’s Hardest Climb – The Shark’s Fin on Meru Central(由金国威撰写)
- Jimmy Chin: why climbing Meru Peak is tougher than Everest
- Mental Floss: 9 Facts About Climbing Mount Meru—And Making a Documentary Out of It
- Alpinist: Shark’s Fin Full Report
- Men's Journal: Climbing Mount Impossible
- Alpine Climbing vs Expedition Mountaineering: Unraveling the Differences
- 《启动:Xbox 的故事》
- 《阿波罗 11 号》
这篇文章最初发表在 JuiceFS 官方博客,点击这里查看原文。
什么是文件系统
当提到文件系统,大部分人都很陌生。但我们每个人几乎每天都会使用到文件系统,比如大家打开 Windows、macOS 或者 Linux,不管是用资源管理器还是 Finder,都是在和文件系统打交道。如果大家有自己动手装过操作系统的话,第一次安装的时候一定会有一个步骤就是要格式化磁盘,格式化的时候就需要选择磁盘需要用哪个文件系统。
维基百科上的关于文件系统的定义是:
In computing, file system is a method and data structure that the operating system uses to control how data is stored and retrieved.
总结一下,文件系统管理的是某种物理存储介质(如磁盘、SSD、CD、磁带等)上的数据。在文件系统中最基础的概念就是文件和目录,所有的数据都会对应一个文件,通过目录以树形结构来管理和组织这些数据。基于文件和目录的组织结构,可以进行一些更高级的配置,比如给文件配置权限、统计文件的大小、修改时间、限制文件系统的容量上限等。
以下罗列了一些在不同操作系统中比较常见的文件系统:
- Linux:ext4、XFS、Btrfs
- Windows:NTFS、FAT32
- macOS:APFS、HFS+
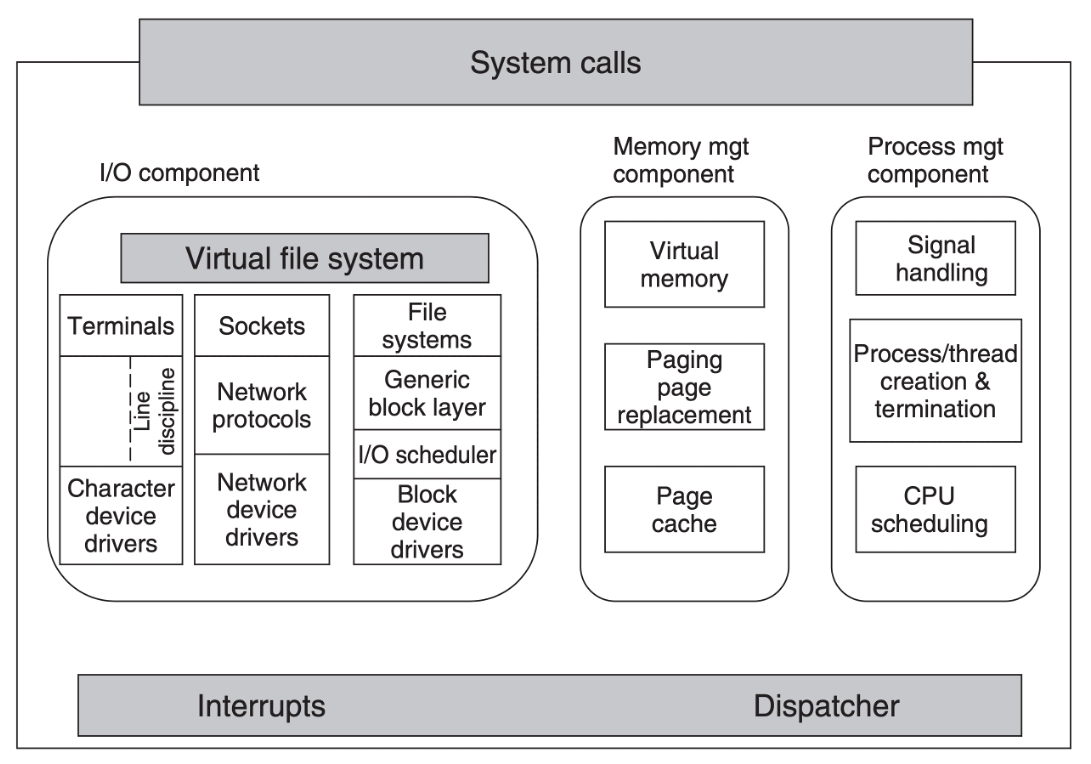
上图是 Linux 内核的架构,左边 Virtual file system 区域,也就是虚拟文件系统简称 VFS。它的作用是为了帮助 Linux 去适配不同的文件系统而设计的,VFS 提供了通用的文件系统接口,不同的文件系统实现需要去适配这些接口。
日常使用 Linux 的时候,所有的系统调用请求都会先到达 VFS,然后才会由 VFS 向下请求实际使用的文件系统。文件系统的设计者需要遵守 VFS 的接口协议来设计文件系统,接口是共享的,但是文件系统具体实现是不同的,每个文件系统都可以有自己的实现方式。文件系统再往下是存储介质,会根据不同的存储介质再去组织存储的数据形式。
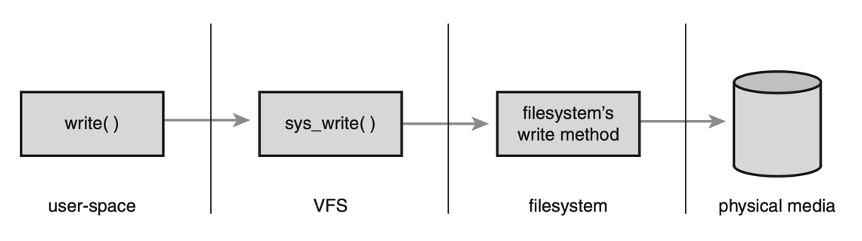
上图是一次写操作的请求流程,在 Linux 里写文件,其实就是一次 write() 系统调用。当你调用 write() 操作请求的时候,它会先到达 VFS,再由 VFS 去调用文件系统,最后再由文件系统去把实际的数据写到本地的存储介质。
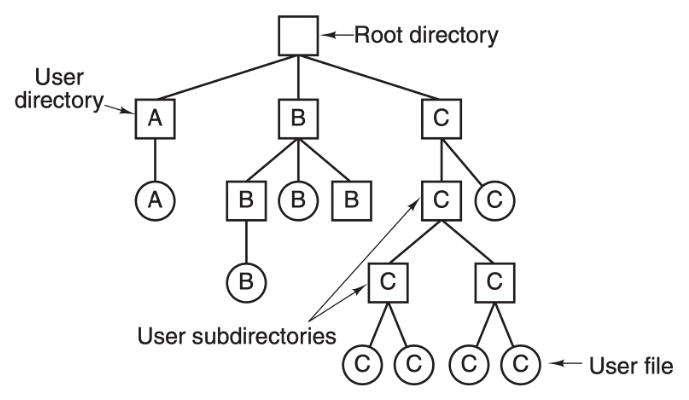
上图是一个目录树的结构,在文件系统里面,所有数据的组织形式都是这样一棵树的结构,从最上面的根节点往下,有不同的目录和不同的文件。这颗树的深度是不确定的,相当于目录的深度是不确定的,是由每个用户来决定的,树的叶子节点就是每一个文件。
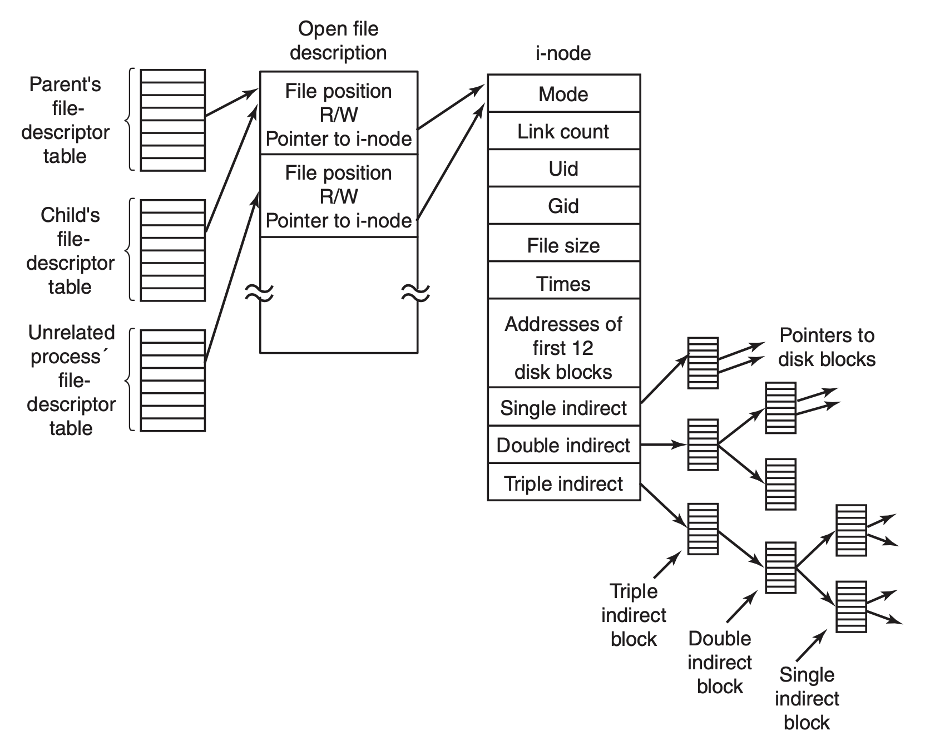
最右边的 inode 就是每个文件系统内部的数据结构。这个 inode 有可能是一个目录,也有可能是一个普通的文件。 Inode 里面会包含关于文件的一些元信息,比如创建时间、创建者、属于哪个组以及权限信息、文件大小等。此外每个 inode 里面还会有一些指针或者索引指向实际物理存储介质上的数据块。
以上就是实际去访问一个单机文件系统时,可能会涉及到的一些数据结构和流程。作为一个引子,让大家对于文件系统有一个比较直观的认识。
分布式文件系统架构设计
单机的文件系统已经能够满足我们大部分使用场景的需求,管理很多日常需要存储的数据。但是随着时代的发展以及数据的爆发增长,对于数据存储的需求也是在不断的增长,分布式文件系统应运而生。
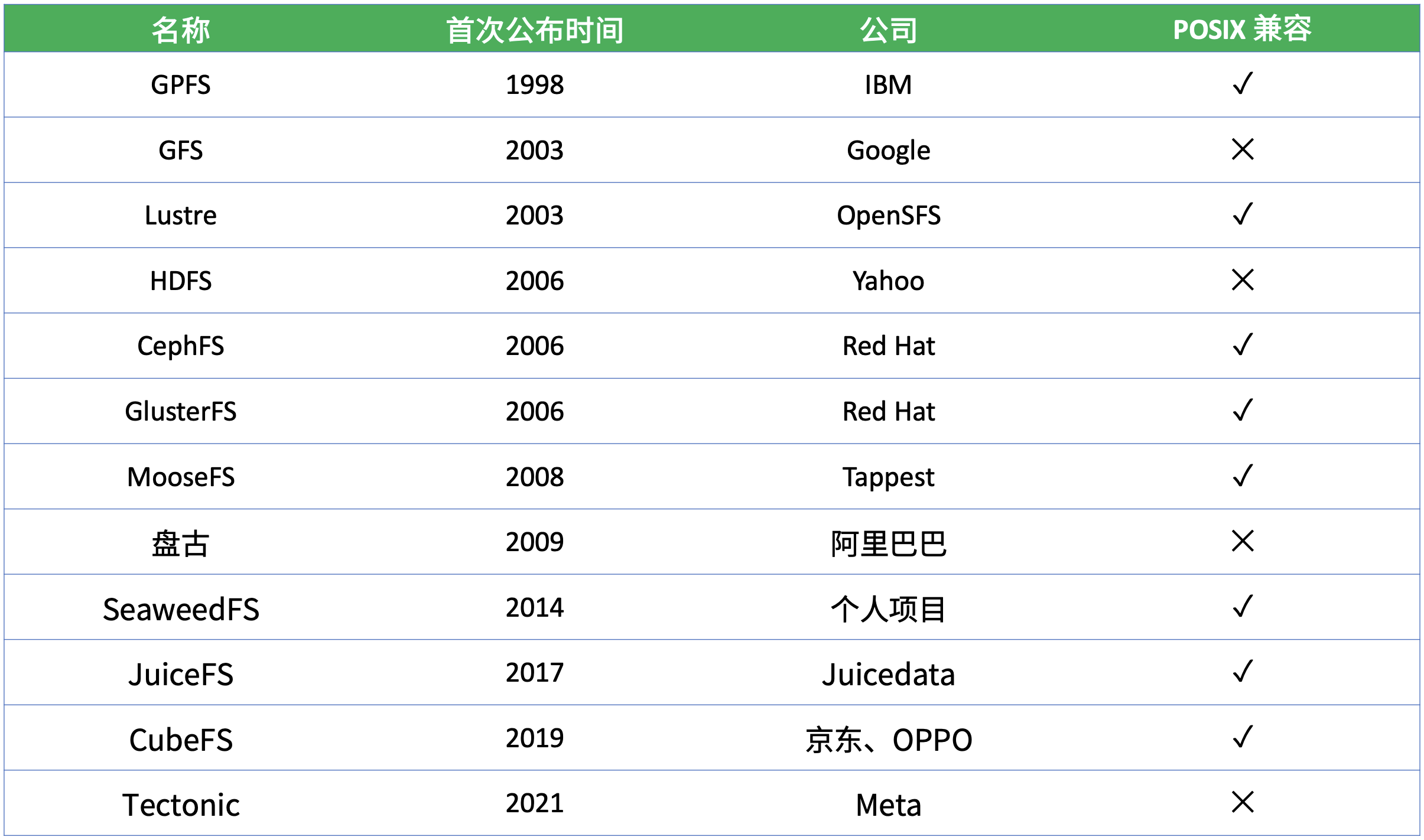
上面列了一些大家相对比较熟悉或者使用比较多的分布式文件系统,这里面有开源的文件系统,也有公司内部使用的闭源产品。从这张图可以看到一个非常集中的时间点,2000 年左右有一大批的分布式系统诞生,这些分布式文件系统至今在我们日常工作中或多或少还是会接触到。在 2000 年之前也有各种各样的共享存储、并行文件系统、分布式文件系统,但基本上都是基于一些专用的且比较昂贵的硬件来构建的。
自 2003 年 Google 的 GFS(Google File System)论文公开发表以来,很大程度上影响了后面一大批分布式系统的设计理念和思想。GFS 证明了我们可以用相对廉价的通用计算机,来组建一个足够强大、可扩展、可靠的分布式存储,完全基于软件来定义一个文件系统,而不需要依赖很多专有或者高昂的硬件资源,才能去搭建一套分布式存储系统。
因此 GFS 很大程度上降低了分布文件系统的使用门槛,所以在后续的各个分布式文件系统上都可以或多或少看到 GFS 的影子。比如雅虎开源的 HDFS 它基本上就是按照 GFS 这篇论文来实现的,HDFS 也是目前大数据领域使用最广泛的存储系统。
上图第四列的「POSIX 兼容」表示这个分布式文件系统对 POSIX 标准的兼容性。POSIX(Portable Operating System Interface)是用于规范操作系统实现的一组标准,其中就包含与文件系统有关的标准。所谓 POSIX 兼容,就是满足这个标准里面定义的一个文件系统应该具备的所有特征,而不是只具备个别,比如 GFS,它虽然是一个开创性的分布式文件系统,但其实它并不是 POSIX 兼容的文件系统。
Google 当时在设计 GFS 时做了很多取舍,它舍弃掉了很多传统单机文件系统的特性,保留了对于当时 Google 搜索引擎场景需要的一些分布式存储的需求。所以严格上来说,GFS 并不是一个 POSIX 兼容的文件系统,但是它给了大家一个启发,还可以这样设计分布式文件系统。
接下来我会着重以几个相对有代表性的分布式文件系统架构为例,给大家介绍一下,如果要设计一个分布式文件系统,大概会需要哪些组件以及可能会遇到的一些问题。
GFS
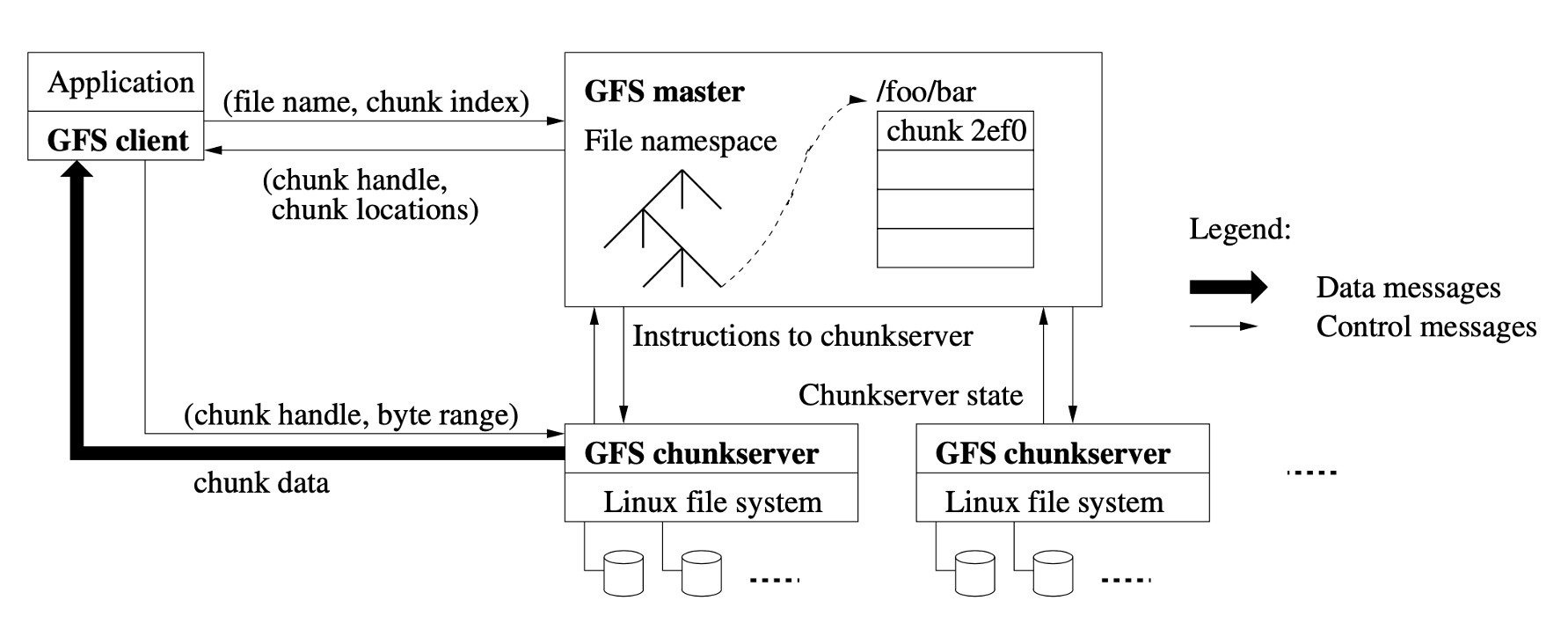
首先还是以提到最多的 GFS 为例,虽然它在 2003 年就公布了,但它的设计我认为至今也是不过时的,有很多值得借鉴的地方。GFS 的主要组件可以分为三块,最左边的 GFS client 也就是它的客户端,然后就是中间的 GFS master 也就是它的元数据节点,最下面两块是 GFS chunkserver 就是数据实际存储的节点,master 和 chunkserver 之间是通过网络来通信,所以说它是一个分布式的文件系统。Chunkserver 可以随着数据量的增长不断地横向扩展。
其中 GFS 最核心的两块就是 master 和 chunkserver。我们要实现一个文件系统,不管是单机还是分布式,都需要去维护文件目录、属性、权限、链接等信息,这些信息是一个文件系统的元数据,这些元数据信息需要在中心节点 master 里面去保存。Master 也包含一个树状结构的元数据设计。
当要存储实际的应用数据时,最终会落到每一个 chunkserver 节点上,然后 chunkserver 会依赖本地操作系统的文件系统再去存储这些文件。
Chunkserver 和 master、client 之间互相会有连接,比如说 client 端发起一个请求的时候,需要先从 master 获取到当前文件的元数据信息,再去和 chunkserver 通信,然后再去获取实际的数据。在 GFS 里面所有的文件都是分块(chunk)存储,比如一个 1GB 的大文件,GFS 会按照一个固定的大小(64MB)对这个文件进行分块,分块了之后会分布到不同的 chunkserver 上,所以当你读同一个文件时其实有可能会涉及到和不同的 chunkserver 通信。
同时每个文件的 chunk 会有多个副本来保证数据的可靠性,比如某一个 chunkserver 挂了或者它的磁盘坏了,整个数据的安全性还是有保障的,可以通过副本的机制来帮助你保证数据的可靠性。这是一个很经典的分布式文件系统设计,现在再去看很多开源的分布式系统实现都或多或少有 GFS 的影子。
这里不得不提一下,GFS 的下一代产品: Colossus。由于 GFS 的架构设计存在明显的扩展性问题,所以 Google 内部基于 GFS 继续研发了 Colossus。Colossus 不仅为谷歌内部各种产品提供存储能力,还作为谷歌云服务的存储底座开放给公众使用。Colossus 在设计上增强了存储的可扩展性,提高了可用性,以处理大规模增长的数据需求。下面即将介绍的 Tectonic 也是对标 Colossus 的存储系统。篇幅关系,这篇博客不再展开介绍 Colossus,有兴趣的朋友可以阅读官方博客。
Tectonic
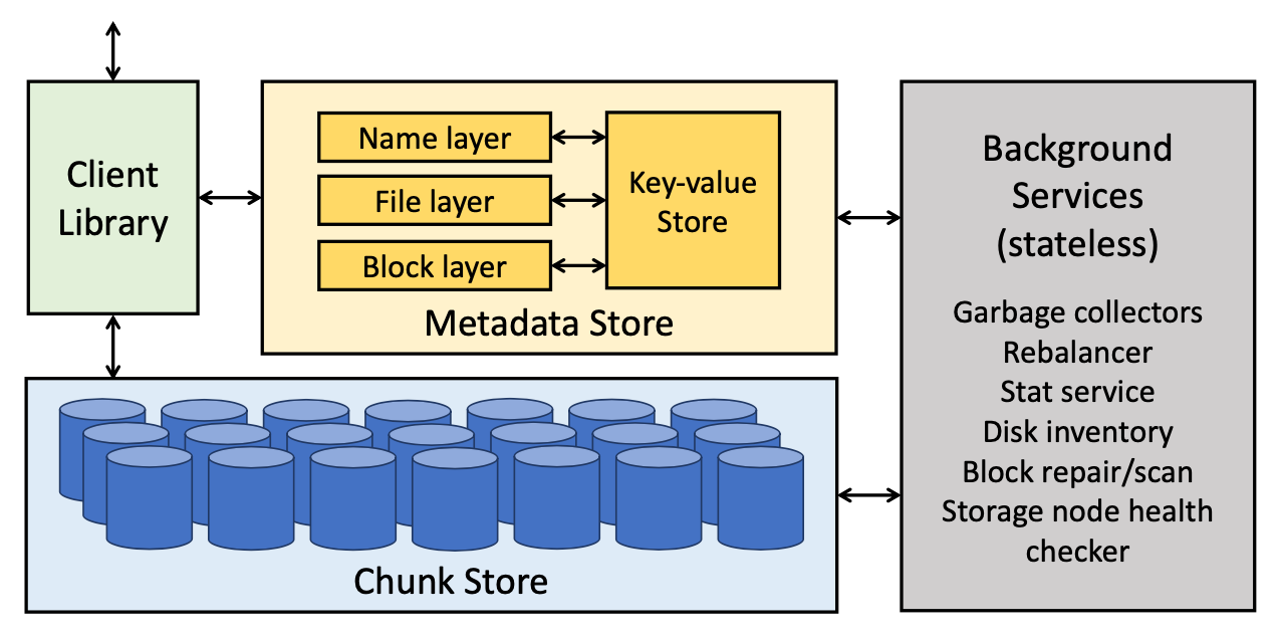
Tectonic 是 Meta(Facebook)内部目前最大的一个分布式文件系统。Tectonic 项目大概在 2014 年就开始做了(之前被叫做 Warm Storage),但直到 2021 年才公开发表论文来介绍整个分布式文件系统的架构设计。在研发 Tectonic 之前,Meta 公司内部主要使用 HDFS、Haystack 和 f4 来存储数据,HDFS 用在数仓场景(受限于单集群的存储容量,部署了数十个集群),Haystack 和 f4 用在非结构化数据存储场景。Tectonic 的定位即是在一个集群里满足这 3 种存储支撑的业务场景需求。
和 GFS 一样,Tectonic 也主要由三部分构成,分别是 Client Library、Metadata Store 和 Chunk Store。
Tectonic 比较创新的点在于它在 Metadata 这一层做了分层处理,以及存算分离的架构设计。从架构图可以看到 Metadata 分了三层:Name layer、File layer 和 Block layer。传统分布式文件系统会把所有的元数据都看作同一类数据,不会把它们显式区分。在 Tectonic 的设计中,Name layer 是与文件的名字或者目录结构有关的元数据,File layer 是跟当前文件本身的一些属性相关的数据,Block layer 是每一个数据块在 Chunk Store 位置的元数据。
Tectonic 之所以要做这样一个分层的设计是因为它是一个非常大规模的分布式文件系统,特别是在 Meta 这样的量级下(EB 级数据)。在这种规模下,对于 Metadata Store 的负载能力以及扩展性有着非常高的要求。
第二点创新在于元数据的存算分离设计,前面提到这三个 layer 其实是无状态的,可以根据业务负载去横向扩展。但是上图中的 Key-value Store 是一个有状态的存储,layer 和 Key-value Store 之间通过网络通信。
Key-value Store 并不完全是 Tectonic 自己研发的,而是用了 Meta 内部一个叫做 ZippyDB 的分布式 KV 存储来支持元数据的存储。ZippyDB 是基于 RocksDB 以及 Paxos 共识算法来实现的一个分布式 KV 存储。Tectonic 依赖 ZippyDB 的 KV 存储以及它提供的事务来保证整个文件系统元信息的一致性和原子性。
这里的事务功能是非常重要的一点,如果要实现一个大规模的分布式文件系统,势必要把 Metadata Store 做横向扩展。横向扩展之后就涉及数据分片,但是在文件系统里面有一个非常重要的语义是强一致性,比如重命名一个目录,目录里面会涉及到很多的子目录,这个时候要怎么去高效地重命名目录以及保证重命名过程中的一致性,是分布式文件系统设计中是一个非常重要的点,也是业界普遍认为的难点。
Tectonic 的实现方案就是依赖底层的 ZippyDB 的事务特性来保证当仅涉及单个分片的元数据时,文件系统操作一定是事务性以及强一致性的。但由于 ZippyDB 不支持跨分片的事务,因此在处理跨目录的元数据请求(比如将文件从一个目录移动到另一个目录)时 Tectonic 无法保证原子性。
在 Chunk Store 层 Tectonic 也有创新,上文提到 GFS 是通过多副本的方式来保证数据的可靠性和安全性。多副本最大的弊端在于它的存储成本,比如说你可能只存了1TB 的数据,但是传统来说会保留三个副本,那么至少需要 3TB 的空间来存储,这样使得存储成本成倍增长。对于小数量级的文件系统可能还好,但是对于像 Meta 这种 EB 级的文件系统,三副本的设计机制会带来非常高昂的成本,所以他们在 Chunk Store 层使用 EC(Erasure Code)也就是纠删码的方式去实现。通过这种方式可以只用大概 1.2~1.5 倍的冗余空间,就能够保证整个集群数据的可靠性和安全性,相比三副本的冗余机制节省了很大的存储成本。Tectonic 的 EC 设计细到可以针对每一个 chunk 进行配置,是非常灵活的。
同时 Tectonic 也支持多副本的方式,取决于上层业务需要什么样的存储形式。EC 不需要特别大的的空间就可以保证整体数据的可靠性,但是 EC 的缺点在于当数据损坏或丢失时重建数据的成本很高,需要额外消耗更多计算和 IO 资源。
通过论文我们得知目前 Meta 最大的 Tectonic 集群大概有四千台存储节点,总的容量大概有 1590PB,有 100 亿的文件量,这个文件量对于分布式文件系统来说,也是一个比较大的规模。在实践中,百亿级基本上可以满足目前绝大部分的使用场景。

再来看一下 Tectonic 中 layer 的设计,Name、File、Block 这三个 layer 实际对应到底层的 KV 存储里的数据结构如上图所示。比如说 Name layer 这一层是以目录 ID 作为 key 进行分片,File layer 是通过文件 ID 进行分片,Block layer 是通过块 ID 进行分片。
Tectonic 把分布式文件系统的元数据抽象成了一个简单的 KV 模型,这样可以非常好的去做横向扩展以及负载均衡,可以有效防止数据访问的热点问题。
JuiceFS
JuiceFS 诞生于 2017 年,比 GFS 和 Tectonic 都要晚,相比前两个系统的诞生年代,外部环境已经发生了翻天覆地的变化。
首先硬件资源已经有了突飞猛进的发展,作为对比,当年 Google 机房的网络带宽只有 100Mbps(数据来源:The Google File System 论文),而现在 AWS 上机器的网络带宽已经能达到 100Gbps,是当年的 1000 倍!
其次云计算已经进入了主流市场,不管是公有云、私有云还是混合云,企业都已经迈入了「云时代」。而云时代为企业的基础设施架构带来了全新挑战,传统基于 IDC 环境设计的基础设施一旦想要上云,可能都会面临种种问题。如何最大程度上发挥云计算的优势是基础设施更好融入云环境的必要条件,固守陈规只会事倍功半。
同时,GFS 和 Tectonic 都是仅服务公司内部业务的系统,虽然规模很大,但需求相对单一。而 JuiceFS 定位于服务广大外部用户、满足多样化场景的需求,因而在架构设计上与这两个文件系统也大有不同。
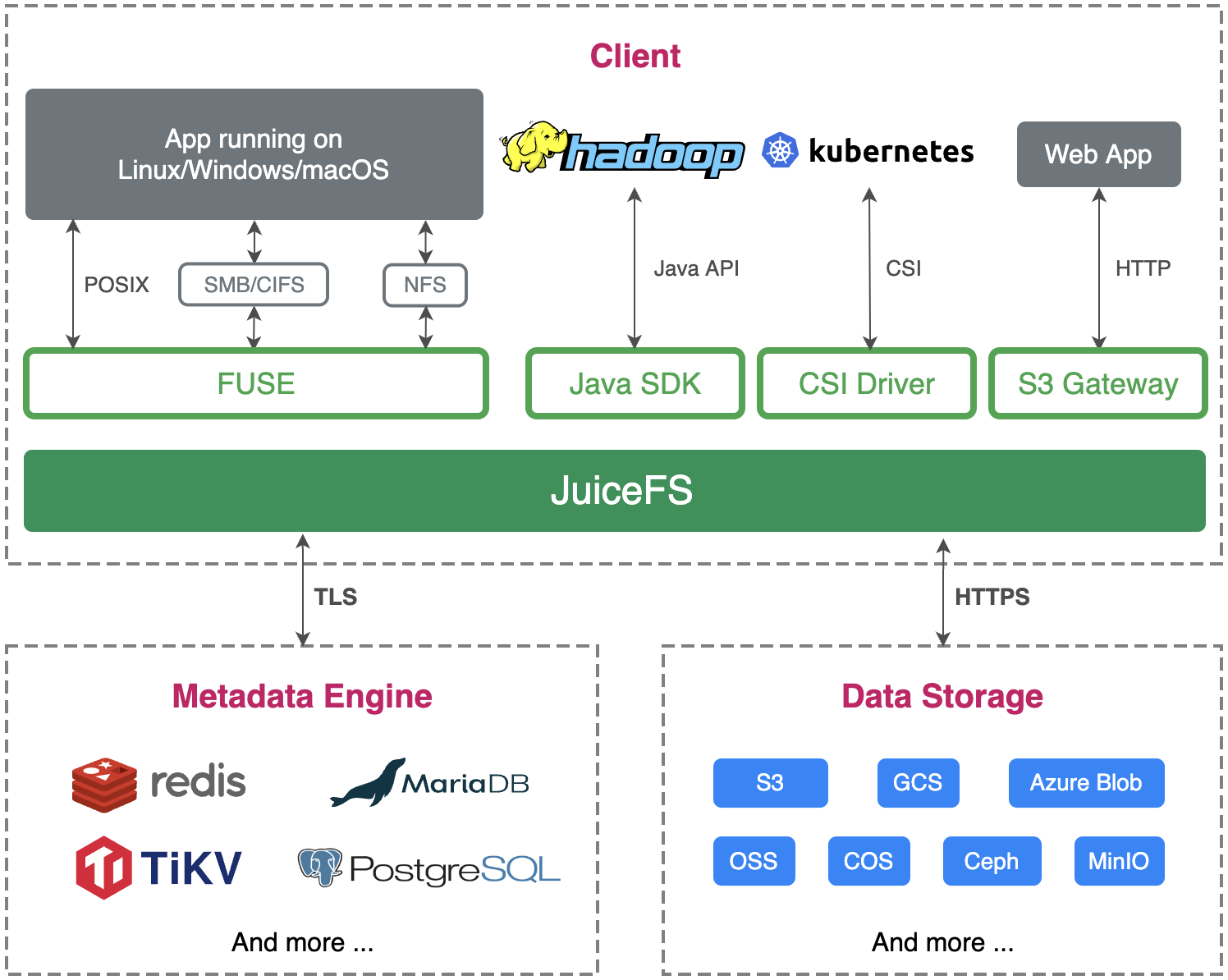
基于这些变化和差异,我们再来看看 JuiceFS 的架构。同样的,JuiceFS 也是由 3 部分组成:元数据引擎、数据存储和客户端。虽然大体框架上类似,但其实每一部分的设计 JuiceFS 都有着一些不太一样的地方。
首先是数据存储这部分,相比 GFS 和 Tectonic 使用自研的数据存储服务,JuiceFS 在架构设计上顺应了云原生时代的特点,直接使用对象存储作为数据存储。前面看到 Tectonic 为了存储 EB 级的数据用了 4000 多台服务器,可想而知,如此大规模存储集群的运维成本也必然不小。对于普通用户来说,对象存储的好处是开箱即用、容量弹性,运维复杂度陡然下降。对象存储也支持 Tectonic 中使用的 EC 特性,因此存储成本相比一些多副本的分布式文件系统也能降低不少。
但是对象存储的缺点也很明显,例如不支持修改对象、元数据性能差、无法保证强一致性、随机读性能差等。这些问题都被 JuiceFS 设计的独立元数据引擎,Chunk、Slice、Block 三层数据架构设计,以及多级缓存解决了。
其次是元数据引擎,JuiceFS 可使用一些开源数据库作为元数据的底层存储。这一点和 Tectonic 很像,但 JuiceFS 更进了一步,不仅支持分布式 KV,还支持 Redis、关系型数据库等存储引擎,让用户可以灵活地根据自己的使用场景选择最适合的方案,这是基于 JuiceFS 定位为一款通用型文件系统所做出的架构设计。使用开源数据库的另一个好处是这些数据库在公有云上通常都有全托管服务,因此对于用户来说运维成本几乎为零。
前面提到 Tectonic 为了保证元数据的强一致性选择了 ZippyDB 这个支持事务的 KV 存储,但 Tectonic 也只能保证单分片元数据操作的事务性,而 JuiceFS 对于事务性有着更严格的要求,需要保证全局强一致性(即要求跨分片的事务性)。因此目前支持的所有数据库都必须具有单机或者分布式事务特性,否则是没有办法作为元数据引擎接入进来的(一个例子就是 Redis Cluster 不支持跨 slot 的事务)。基于可以横向扩展的元数据引擎(比如 TiKV),JuiceFS 目前已经能做到在单个文件系统中存储 200 多亿个文件,满足企业海量数据的存储需求。

上图是使用 KV 存储(比如 TiKV)作为 JuiceFS 元数据引擎时的数据结构设计,如果对比 Tectonic 的设计,既有相似之处也有一些大的差异。比如第一个 key,在 JuiceFS 的设计里没有对文件和目录进行区分,同时文件或目录的属性信息也没有放在 value 里,而是有一个单独的 key 用于存储属性信息(即第三个 key)。
第二个 key 用于存储数据对应的块 ID,由于 JuiceFS 基于对象存储,因此不需要像 Tectonic 那样存储具体的磁盘信息,只需要通过某种方式得到对象的 key 即可。在 JuiceFS 的存储格式中元数据分了 3 层:Chunk、Slice、Block,其中 Chunk 是固定的 64MiB 大小,所以第二个 key 中的 chunk_index 是可以通过文件大小、offset 以及 64MiB 直接计算得出。通过这个 key 获取到的 value 是一组 Slice 信息,其中包含 Slice 的 ID、长度等,结合这些信息就可以算出对象存储上的 key,最终实现读取或者写入数据。
最后有一点需要特别注意,为了减少执行分布式事务带来的开销,第三个 key 在设计上需要靠近前面两个 key,确保事务尽量在单个元数据引擎节点上完成。不过如果分布式事务无法避免,JuiceFS 底层的元数据引擎也支持(性能略有下降),确保元数据操作的原子性。
最后来看看客户端的设计。JuiceFS 和另外两个系统最大的区别就是这是一个同时支持多种标准访问方式的客户端,包括 POSIX、HDFS、S3、Kubernetes CSI 等。GFS 的客户端基本可以认为是一个非标准协议的客户端,不支持 POSIX 标准,只支持追加写,因此只能用在单一场景。Tectonic 的客户端和 GFS 差不多,也不支持 POSIX 标准,只支持追加写,但 Tectonic 采用了一种富客户端的设计,把很多功能都放在客户端这一边来实现,这样也使得客户端有着最大的灵活性。此外 JuiceFS 的客户端还提供了缓存加速特性,这对于云原生架构下的存储分离场景是非常有价值的。
结语
文件系统诞生于上个世纪 60 年代,随着时代的发展,文件系统也在不断演进。一方面由于互联网的普及,数据规模爆发式增长,文件系统经历了从单机到分布式的架构升级,Google 和 Meta 这样的公司便是其中的引领者。
另一方面,云计算的诞生和流行推动着云上存储的发展,企业用云进行备份和存档已逐渐成为主流,一些在本地机房进行的高性能计算、大数据场景,也已经开始向云端迁移,这些对性能要求更高的场景给文件存储提出了新的挑战。JuiceFS 诞生于这样的时代背景,作为一款基于对象存储的分布式文件系统,JuiceFS 希望能够为更多不同规模的公司和更多样化的场景提供可扩展的文件存储方案。
]]>详细内容请访问:https://maybe.news/issues/sp-0。
]]>缘起
由于工作的原因,我的微信里已经累积了数量可观的微信群,微信好友数也噌噌往上涨,已经逼近 1000 大关1。日常工作很大一部分都是在微信中进行,因此很长一段时间我都是严重依赖微信客户端来工作的,准确说是桌面版的微信客户端,应该没人想用手机 app 来处理工作。但一直有几个问题困扰着我,这些问题其实在我之前在某家公司工作时也有过,当时这家公司的内部聊天工具也是微信2。具体来说有这么几个问题。
公私不分
我对于微信的定位主要还是一个私人的聊天工具,因此我一直强烈反对用微信来工作。当年在知乎工作时就大力推广 Slack,虽然 Slack 在国内的体验一直不太好。就算不用 Slack,现在国内也已经有各种企业聊天工具可供选择。但为什么还是有很多人用微信来工作呢?很多时候不是不想选,而是没得选。我就属于这种情况,虽然公司内部以 Slack 沟通为主,但是与很多外部客户沟通就只能通过微信。
功能过盛以及缺失
这个问题和上一个问题互相关联,本质上微信并不是为工作场景设计,因此它提供的很多功能是「多余」的,甚至是一种干扰,同时又「缺失」了很多在工作场景中需要的功能。举个例子,我希望把不同类型的沟通分组便于快速查找和消息隔离(比如客户群是一个分组,私聊是另一个分组),同时我还希望能够针对这些工作相关的聊天信息单独设置通知(比如在非工作时间关闭推送,因为大部分消息都是不需要立即回复的)。再比如一直被呼唤了很久的聊天历史记录及多设备消息同步,前几天还看到一个传闻说微信可能推出付费方案来帮你保存历史聊天记录3。
精力分散
国内的大厂都有一个「坏毛病」,喜欢在一个应用里塞各种莫名其妙的功能,关于这一点已经在我之前的一篇文章中吐槽过。自认我不是一个自制力特别强的人,如果呈现太多难免分心,所谓眼不见心不烦,那些与工作沟通不相干的东西还是暂时不看比较好(或者说没必要非得在工作时间看)4。
没法自动化
用过 Slack 的人都知道,一个有开放 API、能够集成各种自动化组件的聊天工具将会变得非常强大,微信显然不是一个开放的应用,腾讯也不希望针对个人用户开放这样的功能。
所以该怎么办?
作为一个依然怀揣 DIY 念想的中年人5,还是想靠一些外部工具来实现我的需求,如果没有现成的那就自己鼓捣一个。一个显而易见的事实是,微信官方肯定不提供 API,因此只能依赖民间力量。所幸经过不太长时间的搜索我发现了 Wechaty 这个开源项目,简单讲 Wechaty 做的事情就是提供由一群热心网友维护的非官方微信 API,当然现在 Wechaty 已经不仅限于支持微信,也支持很多其它聊天工具,但我关注的主要还是微信。
Wechaty 的一个核心概念是「Puppet」,你可以把它理解为一个代理,负责帮你和实际的聊天工具通信。同一个聊天工具可能有多种 Puppet 实现,比如微信,可以是基于微信网页版来实现,也可以是基于 Pad 版来,亦或是基于 Windows 版。因此你可以看到其实我们并不能完全脱离微信客户端,只不过通过把微信客户端封装起来用对程序更友好的方式呈现。目前我用的是基于微信网页版的 puppet。
需要注意的是,Wechaty 并不能让同一个微信帐号在多个客户端登录,也就是不能同时在 Wechaty 及常规的客户端中登录。另外由于微信的限制,不同的 puppet 实现可能存在功能差异,关于这一点后面会讲到。
能做什么?
既然有了 API,那就可以开开脑洞了。
首先所有微信消息都可以任意转发到任何聊天工具,因此我根据一些特定的关键词把所有与工作有关的消息都转发到了 Slack 上,再通过 Slack 中不同的频道来对消息进行分组管理。除了文本消息,微信还有一些其它类型的消息,如图片、文件,这些也可以转发到 Slack 上,只不过相比文本消息需要做一些特殊处理(如通过 Slack 的 files.upload API 上传文件)。
一些特殊的字符或者内容也需要做特别处理,如微信表情、emoji、换行符、微信公众号文章,避免在 Slack 上看到一串 HTML 标签。微信还会自作主张把一些并不是 URL 的文本封装成 <a> 标签,导致一些显示问题,也需要单独处理。
接收到消息以后是否可以在 Slack 中直接回复呢6?当然可以,但这里就得依赖 Slack 的一些 API 来实现了,在经过一番研究和权衡以后我决定还是用最原始的 message API 来实现,有点类似于早年的 IRC,通过某些关键词来触发机器人做特定的事情。举个栗子,当在一个 Slack thread 中发送以 re: 开头的消息时,就代表这是一条回复,会根据这个 thread 的父消息来判断具体回复给谁(某个人或者某个群)。也可以直接发送消息不依赖 Slack thread,我定义的语法是类似 to: [张三] XXX 这样的格式。这种方式相比直接回复消息稍微麻烦一些,但有一个好处是可以实现群发,也就是刚才命令中的接收者可以是多个。
如果想在回复的时候同时 @ 某个人呢?继续修改上面的命令,以 re: 为例,在后面可以加上你想要 @ 的人,也就是变成 re: @[张三] 这样的格式。
如果想发送图片或者文件呢?也没问题,Slack 的 file 对象包含很多信息,最主要的是 url_private 和 name,有了这两个就可以把文件下载下来,然后通过 Wechaty 的 API 上传到微信。一个额外功能是 Slack 支持在一条消息中附带多个文件,也就能实现一次发送多个文件到微信。
怎么知道消息是否发送成功呢?感谢 Slack,每条消息都可以有 reaction,这些 reaction 其实就是 emoji,因此我们可以根据不同的发送状态添加不同的 emoji,比如发送成功就用一个绿色的勾,发送失败就用一个红色的叉。
至此基本的聊天功能其实已经实现了,剩下的就是一些高级功能,比如搜索联系人、搜索群、修改联系人的备注、修改群名称、邀请人入群、查看群成员等,这些也都可以通过 Wechaty 来实现。
甚至可以脑洞再开大一些,女儿的学校老师每天都会发一些当天的照片和视频到微信群里,这些内容我都想永久保存下来。常规的做法只能是通过微信客户端手动一个一个下载,如果是在手机上保存的,可能还需要再备份到远端的存储。有了 Wechaty 以后我可以直接将这些文件自动保存都家里的 NAS,并且可以根据日期自动归类整理。
不能做什么?
说完能做什么,我们来说说不能做什么。首先最大的前提是任何功能都一定是限定在微信可以实现的假设之下的,常规微信客户端没有办法做到的你也不能做到,比如通过某种方式加一个好友并且在微信中隐藏。
其次某个功能是否能实现就取决于你用的具体是哪个 puppet,拿我用的微信网页版 puppet 为例,就没有办法通过群加好友,以及某个人通过了你的好友申请以后只能重启程序才能看到这个新好友。每次重启以后也不是所有微信群都能看到,只能看到近期活跃的群。
需要注意的是 Wechaty 社区还提供了一些 Puppet Service,这些服务都是必须付费才能使用的,好处是能实现某些免费 puppet 不能实现的功能。但是出于隐私安全7以及灵活性的考虑,我没有使用这些服务。
不要用来做什么?
最后讲讲不要用来做什么,技术可以推动进步,也可以成为「害人」的工具。你的所有行为都不能违反微信对于一个正常用户的判定,否则你将会面临微信对你的惩处,请遵守一个普通用户应有的行为规范。
P.S. 最新一期 Maybe News 已经鸽了很久了,其实内容很早就已经确定下来,只是一直没有完工,在这里就不做承诺,只希望能够尽快完成。
Footnotes
从本期开始 Maybe News 将会启用新的域名和网站:https://maybe.news,个人博客依然会继续更新,不过不会全文转载。如果你已经订阅过那么不需要做任何事情,也欢迎访问新站点进行订阅。
本期关键词:Tectonic、Redlock、Flexible Paxos、明天的盐。详细内容请访问:https://maybe.news/issues/10。
]]>论文
首先讲讲论文阅读。我阅读论文的经历最早应该追溯到本科上学的时候,当时因为毕业设计的需要读了 Bigtable 的论文,并照猫画虎用 Go 写了一个现在只能称之为玩具的实现。后来工作中断断续续也会听说一些好的论文,但并没有系统地去阅读和整理。最近几年的一份工作因为和 AI 有关,才开始比较频繁地接触业界的论文,并有意识地收集一些我认为比较好的论文。收集的渠道其实可以有很多种,最直接的就是去看每年各个顶会的网站,上面都会列出今年已经接受的论文,类似 OSDI 这种会议还会直接附带 PDF 链接,节省了不少找论文的时间。另外每篇论文最后的「引用」其实也是一个发现宝藏的好场所,一般被好论文引用的论文也都不会差,如果你阅读的都是同一个领域的论文会发现有些论文是会被反复频繁引用的。The Morning Paper 是我最喜欢的博客之一,作者 Adrian Colyer 目前是 Accel 的合伙人,之前是 Pivotal、VMware 和 SpringSource 的 CTO,去年疫情期间停止更新了一段时间,后来恢复了每月更新 2~5 篇的节奏,不过现在又停更了(非常悲痛)。国内的话 D 神的「面向信仰编程」博客也是一个不错的地方,不过相比之下论文数就少了很多。
正如各位所看到的,我会固定在每一期 Maybe News 的开头推荐一篇我近期阅读的认为比较好的论文,我关注的领域也基本围绕在分布式系统、数据库、大数据、AI 这几块。这些论文有新有旧,毕竟逃下的课还是得补上的。每次阅读其实都会有很多疑问,如果有机会的话我会尽量联系上作者寻求答案(比如最新的第 9 期),或者去翻阅作者以前写的相关论文,如果是开源软件也会去社区或者代码里找找。阅读特别是精读一篇论文是需要非常专注的环境的,我现在比较习惯于在上下班的地铁上阅读,用的设备是一台 6 寸的 Kindle。可能会有人觉得看论文是不是最好用大屏,但根据我的体验 6 寸 Kindle 除了在滑动的时候卡一点以外其它都还好,并且这个尺寸和重量在便携性上是非常有优势的,如果换成一台 10 寸或者更大尺寸的平板就没有这么方便了。为了完成一篇论文的笔记,这篇论文会被至少阅读两遍,多的时候读上四五遍也是有可能的。
邮件订阅
邮件订阅是我另一个比较重要的阅读来源,日常订阅了如 Golang Weekly、KubeWeekly、SRE Weekly、Data Science Weekly 等。这些内容我并不一定会立即查看,大部分时候它们都是呆在我的收件箱里1。一般我会定期去查看,如果看到感兴趣的内容会先放到 Instapaper 里(或者类似的 Read It Later 服务)。放到 Instapaper 里有几个好处:首先如果时间来不及可以不用立即都看完,以前我有一个习惯是没看完的浏览器 tab 就这样一直开着,时间长了会发现浏览器里保留了很多 tab,不仅影响机器性能查找的时候也很不方便;另外就是 Instapaper 可以作为一个统一的归档,便于搜索曾经看过的内容;最后我可以用任何我喜欢的阅读器在任何设备上阅读,现在我用的是 Reeder,支持 macOS 和 iOS,支持 RSS 订阅,也支持包括 Instapaper 在内的多种服务,这样很多碎片时间也可以用来阅读文章。不过 Reeder 有一个需要吐槽的地方在于不能记住文章的阅读位置,这样当我下次打开的时候有可能需要再重新滚动到上次阅读的地方。除此之外,Reeder 是一个体验非常棒的工具,我从最早的版本一直用到现在的 Reeder 5。
微信公众号
微信公众号是一个比较特别的存在,不知道从什么时候开始,大家都喜欢通过公众号来发布消息和文章。如果说 Web 2.0 的代表之一是博客,那 Web 3.0 可能就是微信公众号2?但我一直认为微信公众号是违背万维网3精神的,或者说整个移动互联网都是,也有人说万维网早就已经死了4。我曾经尝试过运营一个自己的公众号,基于种种原因目前已经废弃5。一些匪夷所思的限制使得在公众号里撰写和阅读文章变得极不愉快,比如不支持任何形式的外链、发布后不能编辑6、强制需要一个头图、每天推送次数限制、阅读过程中没有消息通知7、在桌面端没有一个好的阅读入口8、封闭的生态9。在我看来公众号并不适合深度阅读,更适合发布一些时效性的消息10,但确实有一些好的内容生产者选择了用公众号作为唯一的发布平台。因此很长一段时间关于怎么比较舒适地阅读公众号文章成了困扰我的问题11,直到最近在看一篇文章介绍如何自己搭建一个公众号的 RSS 服务时,知道了一些可以转成 RSS 的方法。本来也想照着弄一个,但是因为老年人比较懒,不太想 DIY,于是试用了文章中提到的付费服务 WeRSS。经过一段时间的体验,除了文章更新有一定延时12以及看不到评论以外,其它都没啥问题。目前我还是会继续用微信来阅读部分公众号,但基本仅限于时效类的消息,让微信回归聊天的本质而不是一个啥都往里塞的大杂烩。
RSS
Google Reader 虽然死了,但是 RSS 还活着。作为 Web 2.0 时代的「遗老」,我依然保留了用 RSS 的习惯。前面提到微信公众号文章目前我已经是通过 RSS 的方式来阅读,除此之外我还订阅了一些感兴趣的至今依然在更新的博客。但总的来说,用 RSS 的频率已经比以前少了很多。
纸质书籍
自高中毕业以后,我阅读纸质书籍的频率就开始大幅降低(大学的专业书籍除外),以前保持的每月固定购买期刊杂志的习惯也没能得以延续,豆瓣的读书列表也还停留在 2018 年。归根结底可能还是没有养成定期读书的习惯13,相比之下我的另一个朋友在毕业多年以后依然保持着每年阅读一定数量的书籍。看了下家里书架上的藏书,基本包含这么几类:专业工具书、金融、装修、小说、漫画、吉他谱。最近在蹭老婆的漫画书看,是大友克洋的《阿基拉》,虽然已经看过动画,但感觉漫画的内容更加丰富。这里就不立什么 flag 了,有机会的话还是希望以后尽量多看书,把高中的习惯重新捡起来。
除了阅读,最近几年也养成了听播客的习惯,关于这个可以以后再说,如果你喜欢欢迎订阅我的博客。
Footnotes
「Maybe News」是一个定期(或许不定期)分享一些可能是新闻的知识的系列文章,名字来源于我非常喜欢的一个国内的音乐厂牌「兵马司」(Maybe Mars)。你也可以通过邮件订阅它。
Virtual Consensus in Delos
一致性协议是分布式系统领域的核心概念,在之前介绍如何设计一个分布式索引框架的一篇文章中已经简单梳理了一致性协议的不同类别以及一些经典的共识算法。今天要介绍的这篇论文并不是发明了一种新的一致性协议,而是对一致性协议进行了拆解和抽象(即论文标题中 Virtual Consensus 的含义),这个抽象可以简化分布式系统的开发和加快迭代速度。Delos 目前已经作为 Facebook 集群调度管理系统 Twine 的控制平面(control plane)在生产环境中稳定运行数年(Delos 是希腊 Cyclades 群岛中一个岛屿的名称,离 Paxos 岛不远)。本篇论文发表在 2020 年的 OSDI 会议,并获得了当年的最佳论文。
在介绍 Delos 系统之前先讲讲为什么要有 Virtual Consensus 这个概念。现有的分布式系统通常都是基于某一种一致性协议来开发的,比如 ZooKeeper 是基于 Zab、etcd 是基于 Raft、Chubby 是基于 Paxos。同时学术界对于一致性协议的研究并没有中止,不断会有新的协议出现(大部分可能都是基于 Paxos 进行改良)。因为这些系统的分布式协议层和状态复制层是紧耦合的,如果想要从一种一致性协议切换到另一种,基本上是需要重写系统的(当然很多人也喜欢重复造轮子)。时间回溯到 2017 年,当时的 Facebook 需要一个保证一致性、可用性、持久性的分布式系统作为他们的核心控制平面来存储元数据,这个系统要在 6-9 个月之内上线,并且支持持续的迭代。虽然当时已经有一些现成的系统可以选择,比如 ZooKeeper、ZippyDB、UDB(分布式 MySQL)、LogDevice,但这些系统要么不支持复杂的 API(比如 get、put、multi-get、multi-put、scan 等),要么可用性达不到要求。更重要的是每个系统都和某种一致性协议绑定,没法平滑过渡到新的协议。
为了解决上述问题, Delos 提出了 Virtual Consensus 这个概念(以下简称 VC),VC 的目标是可以平滑切换一致性协议(甚至同时使用多种协议),并把一致性协议中很多可以复用的逻辑抽出来,从而降低实现新协议的成本。 VC 把一致性协议分解为了控制平面和数据平面两部分,控制平面负责 leader 选举、配置参数、成员管理等,数据平面负责保证数据的顺序(ordering)以及持久性。在 VC 中控制平面称作「VirtualLog」,这是可以复用的部分;数据平面称作「Loglet」,Loglet 可以用不同的一致性协议(比如 Raft、Paxos)实现,也可以是对其它分布式系统(比如 ZooKeeper、HDFS)的封装。如同虚拟内存一样,VirtualLog 把多个物理的 Logets 映射到一个连续的虚拟的 VirtualLog 地址空间中。对 VirtualLog 的用户来说,这些 Loglets 的细节被 VirtualLog 隐藏了起来 ,看起来就像是一个连续的 log。
VirtualLog 由两部分组成:一个客户端层暴露访问 log 的 API,以及一个管理元数据的 MetaStore。这里的元数据是指从 VirtualLog 地址到 Loglet 的映射关系,多个 Loglets 组成了一个链(chain),类似一个单向链表。随着时间推移,链可能会发生变动(比如从 1 个 Loglet 变成 2 个),MetaStore 在保存每个链时也会有一个对应的版本号,每当需要更新链时需要提供一个更大的版本号,这个更新操作是一个类似 CAS(compare-and-swap)的过程,会和当前版本号进行比较,保证原子性,避免并发冲突。当需要修改链时就会触发「重新配置(reconfiguration)」流程,这个流程分为 3 步:密封(sealing)当前链、把 MetaStore 中的链修改为新的链、从 MetaStore 获取新的链。MetaStore 需要保证容错一致性(fault-tolerant consensus),也就是说得通过类似 Paxos 这样的一致性协议去实现,后面会讲到具体如何实现。
因为 VirtualLog 已经负责了控制平面的工作,Loglet 的职责就比较简单了,只需要保证数据的全局顺序性(total order)以及持久性,不需要承担 leader 选举、成员变更管理等工作,也不需要实现容错一致性,因此实现一个 Loglet 的成本非常低(相比实现一个完整的一致性协议)。但有一个要求必须满足,前面提到在重新配置时需要密封链,这个密封操作是通过发送 seal 命令给 Loglet 实现的,Loglet 负责更新本地的 seal 状态,seal 状态是一个布尔值,也就是说只会有两种取值。为了保证后续不会错误地把新数据添加到已经密封的链,Loglet 需要保证 seal 命令是高可用的(highly available),也就是说确保大多数(quorum)的 Loglet 都更新完成。
在了解完 VC 的概念以后来看看 Delos 是如何实现的。Delos 是一个基于 VC 思想实现的分布式存储系统,可以简单把它理解成类似 etcd、ZooKeeper 的系统。Delos 分为 3 层:API、Core 和 Loglet。API 层提供多种类型的接口,例如 table API、ZooKeeper API;Core 层除了包含 VirtualLog 以外,还有 Delos 自己的 runtime,以及基于 RocksDB 的本地存储;Loglet 层就是各种不同的 Loglet 实现。当 Delos 接收到读写事务(read-write transaction)时会先将数据追加(append)到 VirtualLog,VirtualLog 负责把数据发送给底层的 Loglet(具体 Loglet 怎么处理 append 请求后面会讲),然后 Delos 开始从 VirtualLog 同步(synchronize)日志,每当读到一个事务(这个事务既可能是当前 Delos 节点也可能是其它节点写的)就会执行这个操作并保存到本地的 RocksDB 中,最后当把当前 Delos 节点自己写入的最后一个事务执行完毕后就返回请求。对应的,Delos 接收到只读事务(read-only transaction)时,首先通过 VirtualLog 检查全局日志的末尾(tail)位置是多少,然后与 VirtualLog 同步日志直到达到上一步得到的位置(同步过程中如果遇到写事务就需要更新 RocksDB),最后在本地的 RocksDB 中执行这个读请求并返回结果。可以看到,当处理只读事务时 Delos 节点可能需要与底层 Loglet 同步日志,这显然会对读性能造成影响,为了优化这一步 Delos 会在与 VirtualLog 的一次同步请求中包含多个只读事务,而不是一次同步请求只处理一个事务,极端情况下如果需要同步的日志中不包含任何写事务那其实可以跳过这一步。
前面提到 VirtualLog 需要一个 MetaStore 来保存当前的链状态,Delos 最初是通过外部的 ZooKeeper 服务来作为 MetaStore。后来为了去掉对外部系统的依赖改为了在 Delos 服务中内嵌一个 MetaStore,多个 Delos 服务便构成了一个 MetaStore 集群,并通过 Paxos 来保证容错一致性。
Delos 目前已经实现了 5 种 Loglet:ZKLoglet 基于 ZooKeeper 实现,这是 Delos 最初上线时使用的 Loglet;LogDeviceLoglet 基于 LogDevice 实现;BackupLoglet 基于类似 HDFS 的系统实现,目的是作为日志的冷存;NativeLoglet 顾名思义是最原生的 Loglet,只包含最必要的功能,不依赖任何外部系统,也是目前 Delos 在使用的 Loglet(替代 ZKLoglet);最后是 StripedLoglet,这个 Loglet 其实是多个其它 Loglet 的组合,可以有多种组合方式。论文中详细介绍了后两种 Loglet。
NativeLoglet 由两个组件组成:LogServer 和 Sequencer,这些组件都是独立的服务,并且和 Delos 服务部署在一起(当然也可以分开)。LogServer 负责处理有关日志的各种请求,并将日志持久化到本地磁盘,LogServer 可以有多个,且需要为奇数个(因为涉及到类似投多数票的场景);Sequencer 只有 1 个,职责也只有一个,就是处理 append 请求,后面会详细介绍处理流程。
这里有几个概念需要先介绍一下。当说到一个命令被「本地提交(locally committed)」时表示的是一个 LogServer 已经将这个命令同步到了它的本地日志中。当说到一个命令被「全局提交(globally committed)」时表示这个命令已经被大多数的 LogServer 本地提交,并且这个命令之前的所有命令也都已经全局提交。「全局末尾(global tail)」表示最近一个还没有被全局提交的日志位置,NativeLoglet 的日志是没有空隙的,也就是说从位置 0 开始到全局末尾结束中间的每一个位置都有日志数据。同时每个组件(LogServer、Sequencer、Delos 服务等)都维护了一个 knownTail 变量,这个变量保存的是当前这个组件获取到的全局末尾的值,这些组件之间在交互时都会带上各自的 knownTail,如果发现自己本地的值更小就更新到最新的值。
接下来讲一下 NativeLoglet 支持的几种请求。首先是 append 请求,Delos 服务会将请求发送给 Sequencer,Sequencer 会给每个命令分配一个位置(类似一个计数器),然后 Sequencer 负责转发命令给所有 LogServer,当大多数 LogServer 都正常返回时即表示请求成功。如果大多数 LogServer 都返回说已经密封了,请求会失败。除此之外的其它情况(比如超时、LogServer 请求失败等)Sequencer 都会不断重试直到请求成功或者 NativeLoglet 被密封,重试是幂等的,也就是说同样的命令一定会写入同样的位置。Sequencer 维护了一个请求队列,当收到大多数 LogServer 的返回时即认为这个命令已经全局提交,那些发送给还没有返回结果的 LogServer 的请求就可以忽略了,这样处理可以防止某些特别慢的 LogServer 影响整体性能,同时从这里也能看到每个 LogServer 保存的命令可能是不一样的,对于那些缺失的命令也不需要补上。
然后是 seal 请求。正如前面所介绍的,这个请求是用于密封 Loglet。任何客户端都可以发送这个请求给 LogServer,当大多数 LogServer 都正常返回时即表示请求成功,后续的 append 请求也会失败。需要注意的是当 LogServer 被密封以后,每个 LogServer 本地日志的末尾(tail)可能是不同的。
接着是 checkTail 请求。这个请求会返回全局末尾以及当前 NativeLoglet 的密封状态。任何客户端都可以发送这个请求给 LogServer,并等待大多数 LogServer 返回。一旦大多数 LogServer 返回,checkTail 请求会根据返回结果进行不同的后续处理,这些返回结果会有 3 种可能:全部密封、部分密封、全部未密封。「全部密封」即所有 LogServer 都已经处于密封状态,返回结果中同时也会包含每个 LogServer 的末尾位置,前面介绍 seal 请求已经提到不同 LogServer 密封后的末尾可能是不同的,当 checkTail 发现这种情况时会触发一个修复(repair)操作,对那些有漏掉命令的 LogServer 进行补全(通过从其它 LogServer 拷贝数据过来)。「部分密封」即返回结果中同时存在密封和未密封两种状态,针对这种情况客户端会先发送 seal 请求给 LogServer,然后再次发送 checkTail,一般情况下都会得到全部密封的结果。「全部未密封」即所有 LogServer 都处于未密封状态,此时客户端会从所有 LogServer 返回的末尾位置中挑选最大的那个值,然后等待它自己的 knownTail 达到这个值(论文中并没有具体介绍客户端的 knownTail 是如何更新),如果等待过程中有 LogServer 被密封了就会变成「部分密封」的状态,此时就会按照刚才描述的流程进行处理。
最后是 readNext 请求。客户端已经可以通过 checkTail 获取到全局末尾,因此它会根据这个末尾位置首先请求本地的 LogServer(前面提到过 LogServer 和 Delos 服务是部署在一起的),如果本地的 LogServer 没有这个位置的数据,就会再发送请求给其它 LogServer。
以上就是 NativeLoglet 的设计,因为它不需要具备类似容错一致性这样的特性,Facebook 仅仅用了 4 个月就实现完成并部署到生产环境。当然 LogServer、Sequencer 都有可能出问题,这些错误的检测既有一些内部机制来保证,也有一些外部监控系统来触发。一旦发现问题就会进入重新配置流程,即密封现有 Loglet,创建新的 Loglet 并更新链。
StripedLoglet 是多个 Loglet 的组合,实际上只用了 300 行左右的代码就实现完成。Loglet 的组合可以有多种方式,比如为了避免单个 Sequencer 成为瓶颈,可以把相同的一组 LogServer 看作不同的 NativeLoglet 集群,区别在于不同集群的 Sequencer 不一样;再比如为了对 Loglet 进行分片,达到横向扩展的目的,可以用多组 LogServer,每组只存储部分日志。StripedLoglet 目前并没有在实际生产中使用,更多是作为评估阶段的一个方案。
到这里本篇论文中关于 VC 和 Delos 的介绍就差不多讲完了,但其实还有很多细节没有提到,例如 leader 如何选举、如果处理网络分区、集群成员如何变更、为什么要有密封操作、具体什么时候触发重新配置、如何实现一个 RaftLoglet。Delos 其实是建立在论文第一作者 Mahesh Balakrishnan 多年的研究之上,在来到 Facebook 之前他曾经在微软硅谷研究院以及 VMware 研究院工作,Delos 的很多思想来源于 2012 年的「From Paxos to CORFU: A Flash-Speed Shared Log」这篇论文(一个小八卦,这篇论文的第一作者 Dahlia Malkhi 也是学术界大牛,目前是 Diem Association 的 CTO),以及后续多篇论文。有兴趣的同学可以继续阅读这些论文,另外 OSDI 每篇论文都会有一个来自论文作者的演讲,可以点击这里查看视频。
最后特别感谢 Delos 作者之一 Chen Shen 对本文提出的细致及宝贵的修改意见。
Virtualizing Consensus in Delos for Rapid Upgrades and Happy Engineers
在支持 table API 并成功在 Twine 上应用之后,Delos 的下一个目标是提供 ZooKeeper API,并替代 Facebook 内部使用 ZooKeeper 的场景。Delos 目前已经成为了一个构建分布式数据库的「平台」,基于这个平台实现不同的 API 即可满足不同的场景需求,大部分逻辑都可以复用,比如支持 table API 的数据库 DelosTable,支持 ZooKeeper API 的数据库 Zelos。把 Delos 平台化以后也能让不同团队更加专注于各自的目标,提高开发效率(软件工程第一准则「高内聚低耦合」)。不过理想归理想,现实归现实,在 Zelos 的开发过程中逐渐发现组件的边界并没有那么清晰,很多时候 Zelos 需要依赖对 Delos 平台核心进行修改,使得开发流程受到了很大阻碍。为了解决这个问题,Delos 团队发明了一个新的抽象叫做「log-structured protocol」(LSP?),一层叠加在 VirtualLog 之上的协议,每个协议都会包含一个引擎(engine),且可以像网络栈一样把不同协议进行组合。当应用在请求时,会自上而下经过不同的协议,每一层协议也能带上自己的协议头(header),最终到达 VirtualLog。这个设计有点类似于把 Delos runtime 插件化,不同团队可以根据自己的需求开发不同的插件,这些插件也可以同时被不同团队共享。
RFC: Elastic Horovod
在第 7 期介绍过 Horovod 背后的 Ring Allreduce 算法,从 v0.20.0 开始 Horovod 从框架上原生支持了模型训练弹性伸缩。不管是基于 PS 还是 Ring Allreduce 架构,弹性伸缩一直是分布式模型训练领域的热门问题,特别是对于一个 AI 平台来说,弹性伸缩能最大程度提高集群的资源利用率。当然为了实现弹性并不是说能够动态扩缩容就好了,框架也要做到足够好的容错性,才能不对训练效果造成影响。这篇 RFC 详细介绍了 Elastic Horovod 的设计背景及架构。目前阿里云容器团队开源的 et-operator 已经支持在 K8s 中使用 Elastic Horovod,通过 TrainingJob、ScaleIn 和 ScaleOut 这 3 个 CRD 来动态控制训练集群的规模,不过 et-operator 暂时还不支持自动伸缩,社区有一个 PR 正在解决这个问题。
Scaling Kubernetes to 7,500 Nodes
OpenAI 团队在这篇文章中分享了他们是如何将 K8s 扩展到 7500 个节点,在 2018 年其实他们已经分享过扩展到 2500 个节点的经验。需要注意的是,OpenAI 的 K8s 集群主要服务于 AI 任务,每个 pod 会独占一个 node 的所有资源,类似资源碎片、bin-packing 这样的问题都不存在,调度器并不会成为瓶颈,因此他们的经验不一定适用于所有场景。几个有趣的地方:当集群规模到达 7500 节点时,API server 占用大约 70GB 的内存;尽量避免任何 DaemonSet 与 API server 进行交互,如果有需要可以借助一个中间的缓存服务;kube-prometheus 收集了很多有用的数据,但是其中有很多对于 OpenAI 来说都是没用的,因此他们选择通过 P8s rules 来丢弃一些指标;P8s 经常性出现 OOM,最终定位到问题出在 Grafana 和 P8s 之间的交互,解决方法是 patch P8s;Gang scheduling 用到了 K8s 1.15 以后支持的 scheduling framework 以及其中由阿里云和腾讯贡献的 coscheduling 插件(第 2 期也有做介绍)。
播客文字回顾 | Late Troubles 是陈曦的“中年朋克辛酸”吗?
本篇又名「微软产品经理教你如何上班摸鱼做音乐」,Late Troubles 是 Snapline 乐队主唱陈曦的个人计划,相比 Snapline 的音乐风格,Late Troubles 更加温和。目前陈曦已经移居西雅图,作为一个音乐人、一个父亲、一个上班族,他在这个访谈中表达了自己作为异乡异客的思考、关于家庭的思考、关于音乐制作的思考、疫情对生活的影响等等内容,可能就像 Late Troubles 的音乐一样,这篇访谈让我觉得平实及坦诚,任何光鲜的外表下都会有不尽相同的故事,希望有一天能在国内看到 Late Troubles 的现场演出。
]]>「Maybe News」是一个定期(或许不定期)分享一些可能是新闻的知识的系列文章,名字来源于我非常喜欢的一个国内的音乐厂牌「兵马司」(Maybe Mars)。你也可以通过邮件订阅它。
The Google File System
2003 年的 SOSP 会议上作为一家刚成立 5 年的创业公司,Google 发表了这篇影响深远的论文。论文的第一作者 Sanjay Ghemawat 相比他的同事 Jeff Dean 可能不太为外界所知,但看过他的履历以后就会发现早在 DEC 工作期间他就已经与 Jeff Dean 共事,当 Jeff Dean 在 1999 年加入 Google 后不久 Sanjay Ghemawat 也随即加入,并一起研发了 Google File System(以下简称 GFS)、MapReduce、Bigtable、Spanner、TensorFlow 这些每一个都鼎鼎大名的系统,是当之无愧的 Google 元老。
18 年后的今天再来回顾这篇论文依然能发现很多值得借鉴的地方,作为 GFS 最著名的开源实现,HDFS 近年来虽然已经有了很多自己的改进,但核心架构依然沿用的是这篇论文的思想。让我们回到十几年前,去探求为什么 Google 当时要研发这样一个分布式文件系统。
GFS shares many of the same goals as previous distributed file systems such as performance, scalability, reliability, and availability. However, its design has been driven by key observations of our application workloads and technological environment, both current and anticipated, that reflect a marked departure from some earlier file system design assumptions.
论文开篇的第一段话已经很好地概括了 GFS 设计的初衷,这是一个完全基于 Google 业务特点设计的系统。回想一下 Google 的业务是什么?搜索引擎。搜索引擎依靠的是爬虫抓取大量数据,通过用户输入的关键词在这个庞大的数据库中检索,最后通过 Google 独有的排序算法把搜索结果展示给用户。GFS 面对的业务场景有下面几个特点:
- 组件故障随处可见:存储集群由成百上千台普通商用机器组成(与之对应的是昂贵的超级计算机),再加上应用程序和操作系统的 bug、人为错误、各种硬件故障,系统随时都面临着很多不稳定的因素。因此持续监控、错误检测、容错以及自动恢复就显得尤为重要。
- 大文件为主:GB 级文件非常常见,每个文件通常包含很多应用对象(application objects),比如 web 文档。对于数十亿对象的 TB 级数据集来说,把文件切分成 KB 级大小会使得管理变得非常复杂,即使系统能够支撑这样的量级。因此系统设计的假设、文件块的大小都需要重新衡量。
- 大多数文件都只是追加写而不是覆盖:随机写的场景完全不存在,文件一旦写入,只会涉及读操作,且通常是顺序读。多种类型的数据都具有这样的特征,例如某些数据是被数据分析程序批量扫描、某些数据是由数据流持续生成、某些数据是归档数据、某些数据属于中间结果(由某一台机器生成然后被另一台机器处理)。
Google 当时已经部署了多个 GFS 集群,最大的一个集群有超过 1000 个存储节点以及超过 300TB 的磁盘,同时被数百个客户端访问。
论文的第二章节详细介绍了 GFS 的设计假设,除了前面提到的 3 个以外还包括:
- **业务场景主要包含两种读取模式:大批量的流式读取和小量的随机读取。**对于前一种模式,每次请求一般读取数百 KB 或者 MB 级的数据,同一个客户端的连续请求一般也是读取某个文件的连续区域。而后一种模式通常从文件任意偏移位置读取几 KB 数据,对于那些性能敏感的应用会把多个随机读请求排序后批量发送,避免在单个文件中来来回回。
- 系统需要针对并发追加写同一个文件的场景设计好的语义:典型的应用场景是把 GFS 作为消息队列,数百个生产者并发追加数据到同一个文件;或者多路合并文件,想象一下 MapReduce 的 reduce 阶段。这个文件有可能是边写边读,也有可能是写完以后再读。因此用最小的同步开销保证原子性是非常有必要的。
- 高吞吐比低延时更重要:GFS 面对的大多数应用追求的是高速率批量处理数据,只有少部分应用对于点查有严格的延时要求。
像传统的文件系统一样,GFS 提供包括创建、删除、打开、关闭、读取、写入这样的接口,但是 GFS 并不提供 POSIX 这样的标准 API。文件通过目录结构组织,可以通过路径名来标识某一个文件。除此之外,GFS 还提供快照(snapshot)和原子追加写(record append)功能。
在介绍完 GFS 的设计背景以及假设以后,接下来是详细的 GFS 架构讲解。**GFS 服务端由一个 master 和多个 chunkserver 组成,通过特定的 client 库(实现了 GFS 的文件系统 API)与应用集成。**GFS 是非常经典的分布式系统架构,影响了后来很多系统的设计。
Master 负责维护整个文件系统的元数据(metadata),包括命名空间(namespace)、访问控制(access control)信息、文件到 chunk 的映射以及每一个 chunk 的具体位置(location)。命名空间可以理解为目录结构、文件名等信息。除此之外,master 还承担一些系统级的活动,例如 chunk 的租约(lease)管理、垃圾回收无效 chunk、在不同 chunkserver 之间迁移 chunk。Master 会周期性地与每一个 chunkserver 进行心跳通信,心跳信息中同时还会包含 master 下发的指令以及 chunkserver 上报的状态。元数据都是保存在 master 的内存中,因此 master 的操作都非常快。每个 chunk 的元数据大约会占用 64 字节内存空间,每个文件的命名空间信息也是占用 64 字节左右(因为 master 针对文件名进行了前缀压缩),相对来说内存的开销是很小的,随着文件数的增加对 master 节点进行纵向扩展即可。比较重要的元数据信息(比如命名空间、文件到 chunk 的映射)还会同步持久化操作日志(operation log)到 master 的本地磁盘以及复制到远端机器,保证系统的可靠性,避免元数据丢失。当操作日志增长到一定大小,master 会生成一个检查点(checkpoint)用于加快状态恢复,检查点文件是一个类似 B 树的结构,可以不经过解析映射到内存直接查询。每个 chunk 的具体位置不会被持久化,master 每次启动时会通过请求所有 chunkserver 来获取这些信息。最初设计时其实考虑过持久化 chunk 的位置信息,但是后来发现在 chunkserver 拓扑经常变化(比如宕机、扩缩容)的情况下如何保持 master 和 chunkserver 之间的数据同步是一个难题。此外 GFS 还提供仅用于只读场景的影子(shadow)master,影子 master 的数据不是实时同步,因此不保证是最新的数据。
采用单 master 的架构极大地简化了 GFS 的设计(也成为了之后被人诟病的因素),master 作为掌握全局信息的唯一入口,必须确保最小程度影响读写操作,否则就会变成整个系统的瓶颈。**因此 GFS 的设计是 client 读写数据永远不会经过 master。**实现方式很简单,client 请求 master 获取到具体需要通信(不管是读还是写)的 chunkserver 列表,把这个列表缓存在本地,之后就直接请求 chunkserver。
Chunkserver 这个名字的来历其实是因为 GFS 把文件分割成了多个固定大小的 chunk。每个 chunk 的大小是 64MiB,相比传统文件系统的块(block)大小大了很多(比如 ext4 默认的块大小是 4KiB),同时 master 会为每一个 chunk 分配一个全局唯一的 64 位 ID。Chunkserver 除了将 chunk 存储到本地磁盘上,还会复制到其它 chunkserver,GFS 默认会存储 3 个副本,当然用户也可以为不同的目录指定不同的复制等级。为什么 GFS 会选择 64MiB 这么大的 chunk 大小呢?论文中列举了几个原因:
- 减少 client 与 master 的交互:前面提到 client 不管是读还是写数据都需要首先与 master 通信,GFS 的业务场景通常都是顺序读写大文件,chunk 大小越大 client 就能在 1 次请求中获取到更多的信息。即使是随机读的场景,client 也能更多地缓存 chunk 位置信息。
- 降低 chunkserver 的网络开销:更大的 chunk,client 越可能执行更多的操作,因此可以降低 client 与 chunkserver 之间的 TCP 长连接的网络开销。
- 减少 master 维护的元数据大小:chunk 越大,master 就可以在内存中保存更多元数据。
每个 chunk 以及它的副本有两种角色:主副本(primary replica)和从副本(secondary replica),主副本只有 1 个,其它的都是从副本,至于具体哪个是主副本是由 master 决定的。master 会授权一个租约(lease)给主副本,租约的初始超时时间是 60 秒,但是只要 chunk 还在被修改,主副本可以无限续租,master 也可以随时废除租约。基于主从副本和租约的概念,数据写入 GFS 的流程是:
- Client 请求 master 获取当前 chunk 所有副本所在的 chunkserver 列表,如果目前还没有租约,master 会授权给其中一个副本(也就是说这个副本升级为主副本)。
- Master 将主副本的 ID 以及从副本的位置回复给 client,client 会将这些信息缓存在本地,只有当主副本无法通信或者租约失效时才会再次请求 master。
- Client 发送数据给主从副本所在的全部 chunkserver。发送顺序无所谓,一般是发送给离 client 最近的一个 chunkserver,然后这个 chunkserver 会传递给离它最近的下一个 chunkserver,依此类推。Chunkserver 之间的距离是通过 IP 地址估算出来的,之所以采用这种线性传递数据的方式,目的是最大化网络吞吐。Chunkserver 不会等到一个 chunk 全部接收完毕才发送出去,而是采用管道(pipeline)的方式,只要接收到一定的数据就立即发送。值得一提的是,当时 Google 的网络带宽是 100Mbps,而现在(2021 年)AWS 上的机器网络带宽能达到 25Gbps,是当年的 250 倍。
- 一旦所有副本都回复收到了数据,client 就发送写请求给主副本。这个请求包含了上一步发送的所有数据的标识符,主副本会分配连续的序列号给写请求,并按照序列号的顺序修改它的状态。
- 主副本转发写请求给其它从副本,从副本也会按照相同的序列号顺序修改状态。
- 当所有从副本都回复给主副本,即表示这次写请求已经完成。
- 主副本回复请求给 client。如果任何副本发生了错误也会一并回复,GFS 的客户端会尝试重试。步骤 3~步骤 7 执行时也会有一定的重试机制,避免每次都从头开始。
原子追加写(record append)的流程大体上和上面介绍的一样,区别在于第 4 步时主副本会检查写入以后是否会超过最后一个 chunk 的大小(64MiB),如果没超过就追加到后面,如果超过了会把最后一个 chunk 填充(pad)满,并回复 client 重试。
快照(snapshot)功能基于 copy-on-write 实现,master 通过仅仅复制元数据的方式能够在短时间内完成快照的创建。当 client 需要修改快照数据时,master 会通知所有 chunkserver 本地复制对应的 chunk,新的修改会在复制后的 chunk 上进行。
限于本期的篇幅,还有很多 GFS 的特性没有介绍,例如命名空间管理与锁、副本放置策略(placement policy)、chunk 重新复制(re-replication)、数据均衡(rebalancing)、垃圾回收、高可用等。最后是一个彩蛋,如果你仔细看论文最后的感谢名单,会发现一个熟悉的名字(当然不是 Jeff Dean)。
Colossus: Successor to the Google File System
自从 GFS 的论文发布以来,Google 的数据已经增长了好几个数量级,很显然 GFS 的架构已经无法支撑如此大规模的数据存储。那 Google 下一代的文件存储是什么呢?答案就是 Colossus。这个神秘的项目直到目前为止都没有在公开场合被全面正式地介绍过,我们只能通过很多碎片的信息来拼凑出它的模样,上面链接中的内容即是通过这些信息整理出来的。一些有趣的信息是:元数据服务(Curators)基于 Bigtable;相比 GFS 至少可以横向扩展 100 倍;GFS 依然存在,只不过是用来存储文件系统元数据的元数据(metametadata);Colossus 可以基于另一个 Colossus 构建,就像俄罗斯套娃一样无限嵌套(让我想到了分形);存储数据的服务叫做 D server;默认使用 Reed-Solomon 编码存储数据,也就是通常所说的纠删码(erasure code)。建议配合这个 2017 年的 slide 以及这篇中文博客一起阅读。
Storage Reimagined for a Streaming World
流式计算这几年应该算是红到发紫?看看 Flink 社区的发展便可知晓。不过本期要介绍的不是流式计算,而是流式存储。说到与流式计算有关的存储,首先想到的可能是 Kafka,作为实时数据流的消息总线,Kafka 承担着非常重要的角色。但是 Kafka 也不是完美的,它的诞生其实比流式计算更早。Kafka 2011 年开源,Spark v0.7.0 2013 年发布开始支持 streaming,Flink v0.7.0 2014 年发布开始支持 streaming(跟 Spark 是同一个版本号不知是否是巧合)。因此 Kafka 的很多设计并不是针对流式计算场景优化。比如 topic partition 这个概念,本质上是为了提高读或者写的并发,但是 partition 本身是一个静态配置,并不能做到动态伸缩。再比如 Kafka 的数据存储,目前只支持内存和本地磁盘两种,消费新数据都是从内存,如果是旧数据就可能读磁盘,但是 Kafka 集群的存储容量上限毕竟还是受限于磁盘空间,在流式计算越来越重以及云计算大行其道的今天集群运维是一个难题(某些公司已经自研了 Kafka on HDFS 的方案,比如快手)。Pravega 便这样应运而生,这是一个来自戴尔的开源项目,一些设计亮点是动态 partition 以及自动数据分层(Apache BookKeeper + HDFS)。
Why We Built lakeFS: Atomic and versioned Data Lake Operations
在数据库领域 ACID 和 MVCC 已经不是什么新鲜的概念,但是文件系统领域似乎还是一个属于比较「早期」的阶段,虽然过去已经有类似 ZFS、Btrfs 这样创新的设计,但它们并不是广泛被大众了解以及使用的技术。特别是当云计算以及 S3 这样的「傻瓜」方案出现后,人们似乎已经习惯了开箱即用的产品。数据湖(data lake)这个词汇不知道从什么时候开始流行,对象存储的角色变得越来越重(至少云厂商是这样希望的?)。人们对这个「万能」的存储有着越来越多的期望,但是对象存储并不是万能的。为了解决对象存储的各种问题(这里不赘述具体问题)或者说填补它的一些缺失,越来越多基于对象存储的项目诞生。lakeFS 即是其中一个,lakeFS 希望通过提供类似 Git 的体验来管理对象存储中的数据,并且保证 ACID。比如创建一个数据的「分支」即可实现多版本管理。lakeFS 的开发团队来自以色列(公司官网挺有意思),项目使用 Go 语言实现。一些类似的项目还有 DVC、Quilt 以及 Hanger。
Magnet: A scalable and performant shuffle architecture for Apache Spark
在第 6 期 Maybe News 曾经介绍过 Facebook 的 Cosco,一个给 Hive/Spark 使用的 remote shuffle service 实现。本期介绍的 Magnet 来自 LinkedIn,也是一个 shuffle service。跟 Cosco 的区别在于 Magnet 不是存算分离架构,不依赖外部存储,核心思想是 mapper 把 shuffle 数据先写到本地的 shuffle 服务,然后这些 shuffle 数据会根据某种负载均衡算法推到远端的 shuffle 服务上,远端 shuffle 服务会定期合并(merge)数据,最后 reducer 从远端 shuffle 服务读取数据。这里的「远端」其实是一个相对的概念,有可能 reducer 跟 shuffle 服务在同一个节点上,那就不需要发送 RPC 请求而是直接读取本地磁盘的数据。更多技术细节可以参考 VLDB 2020 的论文,另外 LinkedIn 的工程师也在积极将 Magnet 贡献给 Spark 社区,目前已经合入了几个 PR,具体请参考 SPARK-30602。
支付宝研究员王益:Go+ 可有效补全 Python 的不足
王益目前是蚂蚁集团研究员,同时也是开源项目 SQLFlow 和 ElasticDL 的负责人(这两个项目也很有意思,有兴趣的同学可以去了解了解)。这里介绍的 Go+ 是七牛创始人许式伟发起的开源项目,从 Go+ 的 slogan「the language for data science」就能看出项目的设计初衷。如果说目前什么编程语言在数据科学和机器学习领域最受欢迎,那可能就是 Python 了。但是 Python 的语言特性决定了它可能并不是最适合的,Go+ 依托 Go 语言作为基础,很好地弥补了 Python 的缺失。推荐对机器学习感兴趣的同学看看这篇文章,其中提到的一些八卦历史也很有趣。
]]>本篇是 2021 年 1 月 30 日 Kylin Meetup 的直播回顾,主要介绍 JuiceFS 如何优化 Kylin 4.0 的存储性能。完整 slide 请点击这里查看。
大家好,我是来自 Juicedata 的架构师高昌健,今天给大家分享的主题是「如何使用 JuiceFS 优化 Kylin 4.0 的存储性能」。

首先看一下今天分享的提纲,主要分为几个部分。首先对 Kylin 4.0 以及它在云上面临的挑战进行简单介绍,然后详细介绍一下 JuiceFS 是什么以及为什么我们要在 Kylin 中使用 JuiceFS,最后是一些 benchmark。
Kylin 4.0 架构简介
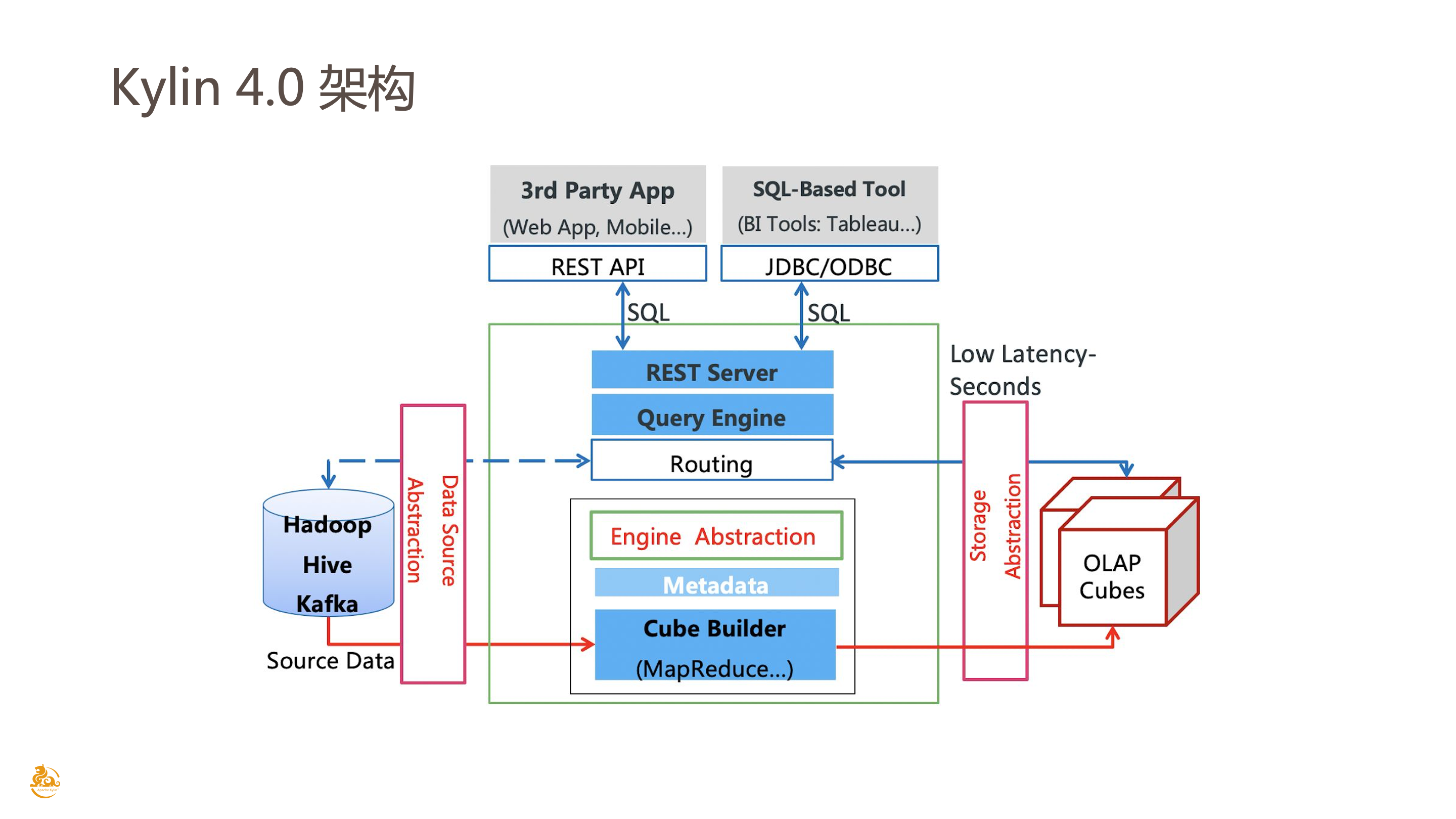
我们先来了解一下 Kylin 4.0 的架构。这是 4.0 的架构图,Kylin 4.0 摒弃了之前基于 HBase 的架构,改为使用 Spark 作为构建以及查询引擎,并且使用 Parquet 作为 Cube 的存储格式直接写到 HDFS 或者对象存储上。Kylin 4.0 的架构不仅性能上有大幅提升,也更加贴合现在云原生的部署方式。

这里想重点讲一下有关存储这块儿的改动,新的存储方式帮助 Kylin 真正实现了存储与计算分离的架构。传统大数据的架构都是存储与计算耦合的,也就是说没有办法单独对存储或者计算资源进行扩缩容。但是在云上使用对象存储替代 HDFS 作为大数据平台的底层存储已经越来越成为主流,也就需要上层计算组件的架构更加灵活。
Kylin on Parquet 在云上的挑战
但是我们也看到云上的对象存储或多或少都存在一些问题,也就为 Kylin 4.0 在云上部署和使用带来了一些挑战。这里我们来看一下对象存储的具体问题。首先很多时候大家会误以为对象存储是完全等价于 HDFS 的,但其实不是,在很多维度上对象存储和 HDFS 都是不一样的。

比如一致性模型,HDFS 是保证强一致性的文件系统,但是对象存储往往是最终一致性,也就是说当你往对象存储中写入新的数据以后并不能立即看到,有可能需要等待一段时间,并且这个等待时间对于用户来说是不可控的,最终一致性会给大数据平台的计算任务带来很多的不确定性,影响任务的稳定性。
然后是元数据操作性能。在大数据场景常见的一些元数据操作,比如 list 是列举某个目录有什么文件、rename 是重命名、delete 是删除,这些元数据操作在对象存储上性能都是不太好的,本质上是因为对象存储是一个 K/V 存储,没法高效实现刚才提到的这些元数据操作。这里比较明显的操作是 rename,因为很多对象存储都不支持重命名,因此真正底层实现的时候都是通过先拷贝原始数据到新的路径,再删除原始数据的方式来实现。这种实现在大数据这种大批量处理数据的场景对性能的影响会比较明显。
然后是数据本地性。Hadoop 因为是存储计算耦合的架构,因此当计算任务被调度时会尽量把计算任务分配到数据节点上,这样就可以提升数据读取的性能。但是对象存储并不提供这样的能力,所有数据都必须通过网络获取,这对于对象存储的带宽有很高的要求,也会对计算的性能造成影响。
对象存储还有一些隐性的点可能不一定被大家关注。对于一个 bucket 中的每个路径其实都有最大的 API 请求频率限制,如果计算任务发送的请求超过了这个限制,就会报错,当然我们可以通过重试或者降低请求并发的方式来一定程度上缓解这个问题,但都是治标不治本,并且也会给业务带来很多不便。对象存储的 API 请求也不是免费的,大数据场景很容易产生大量的请求,这些都会带来一些成本。
Hadoop 兼容性也会成为一个问题,Hadoop 生态具有繁多的组件,不同云厂商的对象存储也可能都会有一些差异,导致上层组件在接入时不一定能完全兼容,甚至出现组件无法正常使用的情况。
JuiceFS 简介

针对刚才提到的这些问题,因此我们开发了 JuiceFS 这样一个项目。这里简单介绍一下 JuiceFS。JuiceFS 是一个开源的云原生分布式文件系统,从今年 1 月初开源以来已经在 GitHub 上积累了超过 2700 个 star。JuiceFS 创新性地基于 Redis 和对象存储构建,同时提供传统文件系统的诸多特性。
例如强一致性,利用独立的元数据管理以及 Redis 的事务特性,JuiceFS 能够确保数据的强一致性。目前 JuiceFS 已经支持市面上几乎所有的对象存储,不管是公有云上的,还是开源对象存储系统,因此对于机房用户来说也是非常友好的。
除了兼容 HDFS 接口以外,JuiceFS 还提供了标准的 POSIX 接口,这是目前 HDFS 以及对象存储都不支持或者支持得不好的一块儿。借助 FUSE 你可以像使用本地文件系统一样把 JuiceFS 挂载到机器上,再通过标准的命令行工具读写数据。此外 JuiceFS 还支持 S3、NFS、Samba 等协议,多种协议的支持使得只用 JuiceFS 一个文件系统就可以同时满足多种业务场景,而不用在不同存储之间重复拷贝数据。
用户访问 JuiceFS 是通过特定的客户端,这个客户端本身也是支持多系统的,包括 Linux、macOS、Windows。在 CPU 架构支持上,除了 x86 以外也支持现在应用广泛的 ARM 平台。
JuiceFS 也提供 K8s CSI 驱动,也就是说在 K8s 平台上你可以很方便地把 JuiceFS 挂载到容器里,这个挂载的 volume 是支持多个容器同时读写的(ReadWriteMany)。同时你也不用担心挂载的 volume 它的一个生命周期,都是由 JuiceFS 的 CSI 驱动来管理,自动地创建、销毁。JuiceFS 的 CSI 驱动很好地满足了容器平台共享存储的需求。
JuiceFS 也具备数据缓存的能力,可以把远端的数据,也就是对象存储的数据缓存到本地,这个后面在介绍 benchmark 的时候会再详细说明数据缓存的能力。最下面是 JuiceFS 的 GitHub 链接。
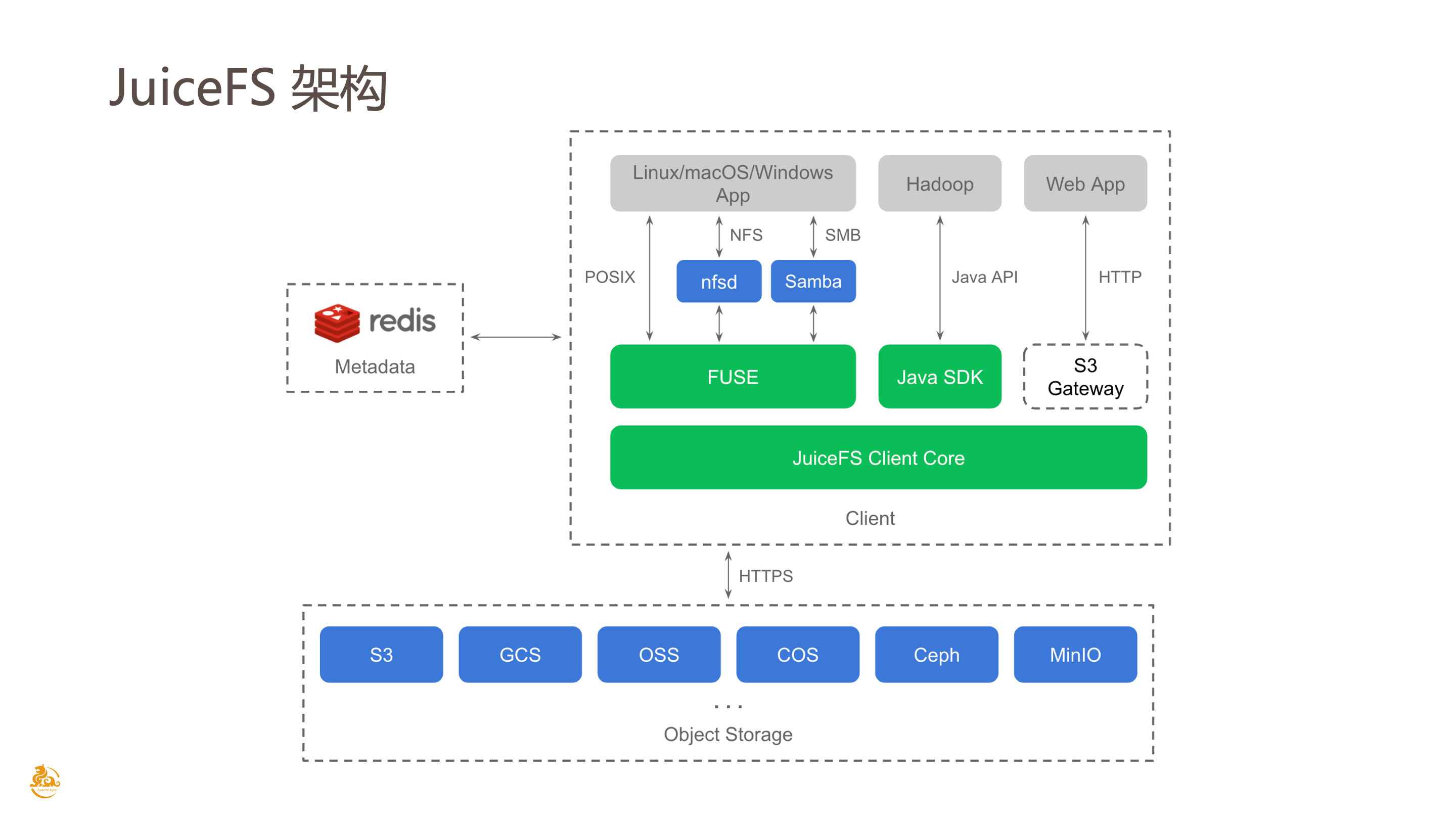
这是 JuiceFS 的架构图。结合刚刚讲到的,JuiceFS 在最底层依赖的是对象存储来作为最基本的数据块存储。JuiceFS 不是原封不动地把数据存储到对象存储上,所有通过 JuiceFS 写入的数据默认会按照 4MiB 一个块来分块,例如写入一个 100MiB 或者 1GiB 的文件会按照 4MiB 这个粒度来切分,切分以后再存储到对象存储上。之所以这样设计很大程度上是因为希望对大文件进行小的分块可以提升读写的吞吐和性能,相比直接一个大文件读取或者写入的话,拆分成小的块之后读写的性能提升还是蛮明显的。
然后在图的左边可以看到是一个 Redis,这里是把 Redis 作为元数据的存储,相当于所有文件系统的元数据都会存到 Redis 中。JuiceFS 依赖 Redis 的事务特性保证所有元数据的操作的原子性,也就是保证元数据的强一致性。
然后右边是 JuiceFS 的客户端。JuiceFS 已经提供了多种客户端,比如 FUSE 是通过挂载来提供 POSIX 接口;Java SDK 是在 Hadoop 环境中使用,我们近期也已经将 Hadoop SDK 开源出来;最右边的是 S3 Gateway,通过这个 gateway 可以对上层提供 S3 兼容的接口。可以看到 JuiceFS 提供了多协议的客户端,这些客户端底层都是共享了同一个实现,也就是图上的 Client Core。除了 Java SDK 以外,客户端整体上都是用 Go 语言实现,Java SDK 底层也是通过 JNI 去调用 Go 语言的接口。
前面提到了数据缓存,意思就是说当从对象存储读取数据时,client 端会自动地把数据缓存到本地配置的某个缓存路径,JuiceFS 也会自动地管理缓存空间,比如说当缓存盘满了之后应该怎么去失效、怎么去维护缓存数据的生命周期,以及保证缓存数据与对象存储之间的一致性。这些都是由 JuiceFS client 端提供的特性。
为什么 Kylin 和 JuiceFS 要一起使用?
下面一个问题就是为什么 Kylin 要和 JuiceFS 一起使用呢?经过前面的介绍,大家可能也或多或少能够想到一些,本质上希望通过 JuiceFS 来解决刚才提到的对象存储的各种问题。所以具体来说 JuiceFS 能给 Kylin 带来的收益有这么几个。

首先是强一致性,也就是相比对象存储的最终一致性来说 JuiceFS 是一个强一致性的文件系统。然后是高性能,JuiceFS 不管是在元数据还是数据的读写上都有很好的性能表现。元数据是基于 Redis 的,Redis 因为是全内存的 K/V 存储,所以元数据操作的性能是非常高的,同时 JuiceFS 在 Redis 之上也做了一些优化。数据的读写 JuiceFS 默认是按照 4MiB 的块来分块存储,在读写上也有蛮多的性能提升。
然后数据本地性也是 JuiceFS 能够带来的一个好处,通过缓存可以把数据缓存到计算节点上,虽然计算节点的缓存空间不一定特别大,但一定程度上也提供了数据本地性。这块儿的具体实现是通过 Java SDK 提供了缓存数据的 location 给上层的调度器(比如 YARN),使得调度器能够知道缓存数据当前是在哪一个计算节点上,可以在调度时把相应的计算任务调度到具有缓存数据的节点上,也就一定程度上实现了数据本地性。即使调度失败了,也有一些进一步的优化,例如在不同计算节点之间组成一个分布式缓存系统,也就是节点互相之间是能够读取对方的缓存数据,对数据读取进行优化,而不是完全依赖底层的对象存储的吞吐和性能。
JuiceFS 同时也是完整兼容 Hadoop 生态的,不管是对于 Hadoop 2.x 和 Hadoop 3.x 这种大版本的变化,还是对于某个 Hadoop 发行版的所有组件都是完全兼容的。因为 JuiceFS 本身提供的就是一个标准的 HDFS 接口,对于上层的组件来说基本上是透明的,也没有任何侵入,就可以当作是 HDFS 来使用。
TCO 低也是 JuiceFS 的一个好处。前面提到对象存储的 API 请求是收费的,这些 API 请求中涵盖了很多元数据的请求, 当使用 JuiceFS 之后这些请求会直接发给元数据服务(也就是 Redis),也就不存在元数据请求的费用。数据的请求依靠比如缓存这样的特性很大程度上减少对对象存储的依赖,整体上来说成本都能有一定优化。
JuiceFS 还支持一些 HDFS 或者对象存储可能不提供的功能。比如快照,快照的意思是可以针对某一个目录创建一个 snapshot,看起来好像是对数据进行了一次拷贝,但底层的实现其实是不存在拷贝的。本质上是一个 copy-on-write 的原理,在创建快照时只是对元数据进行了拷贝,底层是共享的同一份数据,并没有拷贝对象存储上数据。对你对快照进行修改时,就会将原始数据进行拷贝,然后存储修改后的数据。这个特性对于很多场景是非常有帮助的,比如测试、多版本管理。
符号链接在操作系统中是一个常见的功能,通过符号链接可以将一个文件指向另一个文件的路径。在 JuiceFS 上也实现了这个功能,不仅可以将 JuiceFS 的路径映射到另一个路径,也可以链接到任何 JuiceFS 支持的存储上(比如 HDFS、对象存储)。通过 JuiceFS 实现一个统一的文件系统命名空间管理,可以在这一个命名空间中看到多种存储的数据。这其实是一个蛮有用的特性,比如我们对数据进行迁移时是非常有帮助的(可以参考之前的一篇文章)。
本身 JuiceFS 是一个开源的项目,但同时我们也提供一个云上全托管的版本,会将元数据服务进行统一管理,也有一个 web 的控制台可以让大家很方便地使用。这是 JuiceFS 商业版提供的一个功能。
性能比较

然后分享一下之前做的一个 benchmark 结果。先看一下测试环境,这里用了标准的 10GB 大小的 TPC-H 作为数据集,用了 1 台 master,3 台 worker,大概是这样的配置。对比的是 Kylin on OSS 和 Kylin on JuiceFS 的性能。
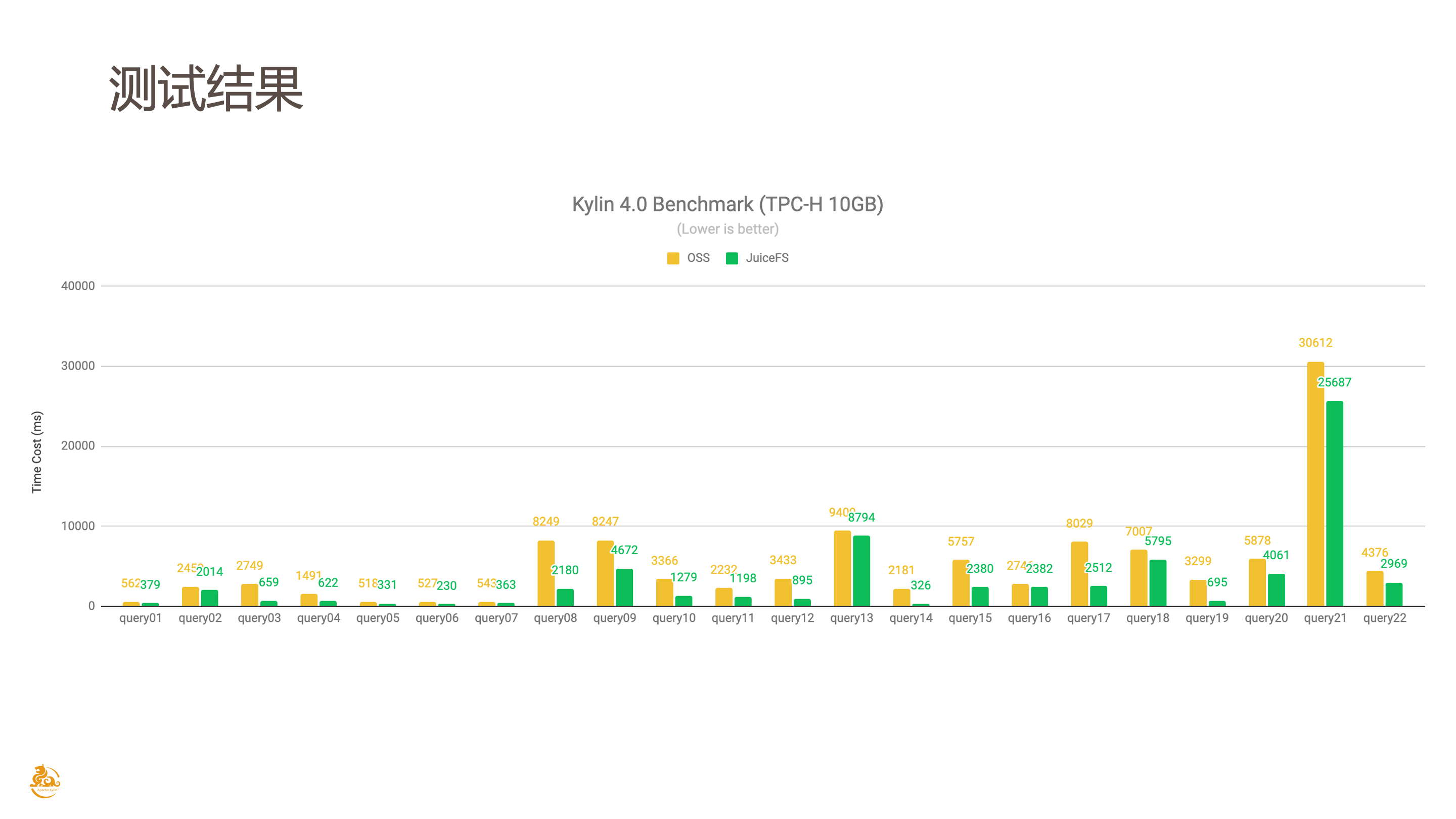
这是最终 benchmark 的对比图,黄色的是 OSS,绿色的是 JuiceFS,图上展示的是 TPC-H 每一个查询的执行时间,这个时间越低越好。

总结一下刚刚提到的测试。因为 Kylin 需要提前构建 cube,我们在测试时遇到 Kylin on OSS 这个方案构建 cube 直接失败了,导致没有办法在 OSS 上构建 cube。最终是通过把 Kylin on JuiceFS 构建完的 cube 拷贝到 OSS 上完成的测试。总的查询时间上 JuiceFS 快 38% 左右,然后看单个查询的执行时间 JuiceFS 最多能够快 85%,平均下来也能快 46% 左右。
未来展望

最后想展望一下未来 JuiceFS 的一些新特性。JuiceFS 已经在性能上进行了很多优化,前面的 benchmark 也能看到,但其实也有很多细粒度的点我们可以优化。比如说查询预读,可以从 JucieFS 的角度预先知道某个查询接下来会读取的文件,也就可以自动地在后台进行一些预读的处理,进一步加速查询的效率。刚刚提到的 P2P 分布式缓存特性也会是接下来在开源版本的 Hadoop SDK 去优化的一个点。最后 JuiceFS 会提供一个 profiling 的工具,这个工具是为了帮助用户更快更简便地调优,发现性能热点,从而针对性地对读写进行优化。
今天的分享就到这里,感谢大家。
]]>「Maybe News」是一个定期(或许不定期)分享一些可能是新闻的知识的系列文章,名字来源于我非常喜欢的一个国内的音乐厂牌「兵马司」(Maybe Mars)。你也可以通过邮件订阅它。
Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores
14 年前,Amazon 发布了 EC2(Elastic Compute Cloud)和 S3(Simple Storage Service)这两个划时代的产品,从此「云计算」这个词开始进入大众的视野,经过十几年的发展已经逐渐被大众所认知与接受。「云」意味着近乎无限的资源,EC2 为用户提供了计算资源,S3 为用户提供了存储资源。传统基于 Hadoop 的大数据平台是将这两种资源绑定在一起的,而迁移到云端以后非常自然地会想到将存储资源转到类似 S3 的对象存储中,从而真正实现存储计算分离的架构,能够更加弹性地管理计算和存储这两种天生异构的资源,既大幅节约了成本还省去了运维 HDFS 集群的各种烦恼。
作为 Spark 的发明者,Databricks 这家商业公司的很多客户同时也是 AWS 的客户,因此有着非常丰富的在大数据场景使用 S3 的经验。这些经验暴露了 S3(或者类似的对象存储)作为 HDFS 替代者的种种缺陷。
对象存储(object store)的用户可以创建很多 bucket,每个 bucket 中存储了很多对象(object),每个对象都会有一个唯一的 key 作为标识。因此对象存储本质上是一个 K/V 存储,这一点非常重要,因为通常的认知都会将对象存储等同于文件系统(file system)。对象存储中的「目录」其实是通过 key 的前缀模拟出来的,虽然对象存储提供类似 LIST 目录这样的 API,底层实现却是遍历相同前缀的对象,这个操作在文件系统中是 O(1) 的时间复杂度,但在对象存储中是 O(n)。更加严重的情况是,S3 的 LIST API 每次请求最多返回 1000 个 key,单次请求延时通常为几十到几百毫秒,因此当处理超大规模的数据集时单单花在遍历上的时间就可能是分钟级。重命名对象或者目录也是一样,文件系统是一个原子操作,对象存储是先拷贝到新路径,再删除原路径的对象,代价非常高。
另一个对象存储严重的问题是一致性模型,S3 的一致性模型是最终一致性。当某个客户端上传了一个新的对象以后,其它客户端并不一定保证能立即 LIST 或者读取这个对象。当一个对象被更新或者删除以后也会发生同样的现象,即使是负责写入的这个客户端自己也有可能遇到。S3 能确保的一致性是 read-after-write,也就是说 PUT 请求产生以后的 GET 请求是保证一定能返回正确数据的。
论文概述了目前大数据存储的 3 种方案:分区目录、自定义存储引擎、元数据在对象存储中,下面分别介绍。
分区目录顾名思义就是将数据按照某些属性进行分区,比如日期。这是大数据领域非常普遍的做法,好处是可以根据分区过滤不需要的数据,也就能减少 LIST 请求的数量。这个方案并没有解决前面提到的对象存储的问题,因此缺点也很明显:不支持跨多个对象的原子操作、最终一致性、低性能、不支持多版本和审计日志。
自定义存储引擎的意思是在云上实现一个独立的元数据服务,类似 Snowflake、JuiceFS 的做法。对象存储只是被当作一个无限容量的块存储,一切元数据操作都依赖这个单独的元数据服务。这个方案的挑战是:
- 所有 I/O 操作都需要经过元数据服务,这会带来额外的请求开销,降低性能和可用性。
- 实现一个与现有计算引擎互通的连接器(connector)需要更高的工程成本
- 用户会因为元数据服务而绑定在某一个特定的服务供应商上,没法直接访问对象存储中的数据。
元数据在对象存储中是 Databricks 提倡的方案,即今天介绍的 Delta Lake。这个方案和前一个的本质区别是不存在一个中心化的元数据服务,元数据是通过「日志」的形式直接存放在对象存储中。从目录结构上来看,Delta Lake 定义了一种特殊的存储格式,例如对于更新或者删除的数据会产生很多小的 delta 文件。这一点上其实跟 Hive 实现 ACID 的设计很像,后者在 2013 年就已经开始开发,而 Delta Lake 项目是 2016 年启动,很难说有没有借鉴的成分。更加类似 Delta Lake 的是另外两个项目:Apache Hudi 和 Apache Iceberg,关于这几个项目的异同后面会有一个更详细的介绍,Databricks 目前宣传的一些 Delta Lake 独有的特性(比如 Z-order clustering)其实并没有开源。
Delta Lake 的思想其实很好理解,本质上是把所有操作都通过日志的形式记录下来,当读取时需要重放这些日志来得到最新的数据状态,最终实现 ACID 的语义。优化的点在于怎么加速整个流程,比如定期合并日志为一个 checkpoint、索引最新的 checkpoint 等。这种把日志作为元数据的设计解决了前面提到的对象存储最终一致性的问题,即只依赖日志来确定具体读取的文件,而不是简单通过 LIST 一个目录。但是从论文描述的场景来看还是有可能因为最终一致性踩坑(因为依然会用到 LIST API),至于这个概率有多大就不知道了,因此我对于是否能根本性解决一致性问题存疑。
写数据的时候有一个地方需要特别注意,日志文件的文件名是递增且全局唯一的 ID,因为写入存在并发,所以需要在这一步保证操作的原子性。根据不同的对象存储有不同的解决方案:
- Google Cloud Storage 和 Azure Blob Store 因为支持原子 put-if-absent 操作,因此可以通过这个 API 实现。
- 对于支持原子 rename 的文件系统(比如 HDFS、Azure Data Lake Storage),可以通过这种方式实现。
- 如果以上功能都不支持(比如 S3),在 Databricks 的企业版本里是通过一个独立的轻量级协调服务(coordination service)来确保 ID 递增的原子性。在开源版本的 Spark 连接器里是通过 Spark driver 来统一分配 ID,这样也能保证在 1 个 Spark 任务里可以并发写。你也可以通过
LogStore这个接口实现一个类似 Databricks 提供的协调服务。因为依赖了一个中心化的服务(虽然只是在写数据时),也一定程度上破坏了 Delta Lake 宣扬的去中心化思想。
由于日志中记录了所有的历史操作,并且数据和日志都是不可变的(immutable),因此 Delta Lake 可以很轻松实现时间旅行(Time Travel)功能,也就是重现某个历史时刻的数据状态。Delta Lake 通过类似 TIMESTAMP AS OF 这种语法的 SQL 可以让用户指定读取某个时间的数据,不过这个 SQL 语法目前在开源版本中还不支持。
Delta Lake 也可以很好地跟流式计算进行结合,不管是生产者还是消费者都可以利用 Delta Lake 的 API 来实现流式写和读数据。当然毕竟因为是 Databricks 开发的产品,目前结合得最好的肯定是 Spark Structured Streaming。你问支持 Flink 吗?至少 Databricks 员工的回答是还在计划中,短期内估计没戏。
最后是性能评测部分。首先评测的是 LIST 大量文件的场景,通过对同一张表进行不同程度地分区来模拟不同量级的文件,评测的引擎是 Hive、Presto、Databricks Runtime(企业版 Spark,以下简称 DR),其中 Hive 和 Presto 读取的数据格式是 Parquet,DR 读取的格式是 Parquet 和 Delta Lake。Hive 在有 1 万个分区时总时间已经超过 1 小时;Presto 稍好一些在 10 万个分区时才超过 1 小时;DR + Parquet 在 10 万个分区时的耗时是 450 秒(得益于并发执行 LIST 请求);DR + Delta Lake 在 1 百万分区时的耗时才 108 秒,如果启用了本地缓存可以进一步缩短到 17 秒,可以看出来优化效果非常明显。这个结果也基本符合预期,毕竟 Delta Lake 主要目标之一就是优化 list 的性能(以及一致性),对象存储在元数据性能上肯定没有优势。
接下来是更接近真实场景的 TPC-DS 测试,数据集大小是 1 TB,测试结果取的是 3 次运行时间的平均值。最后的数据是 Presto + Parquet 耗时 3.76 小时,社区版 Spark + Parquet 耗时 1.44 小时,DR + Parquet 耗时 0.99 小时,DR + Delta Lake 耗时 0.93 小时。DR + Parquet 相比社区版 Spark 快的主要原因是 DR 做了很多运行时和执行计划的优化,相比之下 DR + Delta Lake 并没有比直接读取 Parquet 提升太多,论文中的解释是 TPC-DS 的表分区都不大,不能完全体现 Delta Lake 的优势。
总结一下,Delta Lake 的思想其实并不复杂,也是工业界为了解决对象存储诸多问题的一种尝试,虽然并不能完全解决(比如原子重命名和删除)。在大数据存储上实现 ACID 这一点对于构建实时数仓至关重要,Delta Lake 通过一种简单统一的方式实现了这个需求,而不用像传统的 Lambda 架构一样再单独部署一套存储系统(比如 HBase、Kudu)。但现在流式计算领域的风头已经从 Spark 逐渐转向了 Flink,像 Delta Lake 这种只对 Spark 支持的技术在某种程度上也会限制它的普及,相比之下 Iceberg 和 Hudi 似乎更有竞争力。
Delta Engine: High Performance Query Engine for Delta Lake
前面介绍了 Delta Lake,算是 Databricks 今年一个重量级的开源产品,但其实真正的杀手锏并没有开放出来,也就是这里要介绍的 Delta Engine。简单介绍这是一个在 Delta Lake 之上,基于 Spark 3.0 的计算引擎。Delta Engine 主要包含 3 部分:原生执行引擎(Native Execution Engine),查询优化器(Query Optimizer)以及缓存(Caching)。这个视频重点介绍了原生执行引擎,这个引擎的代号是 Photon,它使用 C++ 编写,并且实现了目前在 OLAP 领域很火的向量化(vectorization)功能,感兴趣的同学强烈建议阅读 MonetDB/X100: Hyper-Pipelining Query Execution 这篇论文,Databricks 厉害的地方在于是跟论文作者 Peter Boncz 一起合作设计。在 30 TB 的 TPC-DS 测试中,Photon 带来了 3.3 倍的性能提升。关于查询优化器以及缓存功能的介绍可以参考 Delta Engine 的文档。
A Thorough Comparison of Delta Lake, Iceberg and Hudi
Iceberg 和 Hudi 是另外两个会经常拿来跟 Delta Lake 做比较的对象,Iceberg 是 Netflix 开源,而 Hudi 是 Uber 开源。它们之间有着诸多相似之处,又有着很多截然不同的设计思想。这个视频来自腾讯云数据湖团队的陈俊杰,比较系统地对比了这 3 种技术。相对来说 Iceberg 的设计是这 3 个里面最中立的,不跟某种特定的格式和引擎绑定,这也是腾讯选择 Iceberg 的原因之一,具体可以看「为什么腾讯看好 Apache Iceberg?」这篇文章。
Bringing HPC Techniques to Deep Learning
深度学习的核心之一是 SGD(Stochastic Gradient Descent),通过把数据集拆分成若干小的集合(mini-batch),再基于这些小集合反复进行前向传播(forward propagation)和反向传播(backpropagation)计算,不断获取新的梯度(gradient)和权重(weight)。分布式训练本质上要解决的问题就是怎么让多机计算的效率线性提升,即所谓的「线性加速比」,理论值当然是 100%,但是实际情况往往差了很多。传统的同步 SGD 在每一轮计算完以后需要把所有梯度汇总,再重新计算新的权重,类似一个 MapReduce 的过程,此时 reducer 需要等待所有 mapper 计算完成,计算性能会随着 mapper 数量的增加而线性下降。怎么解决这个问题呢?这篇 2017 年的旧文介绍的便是影响至今的 Ring Allreduce 算法,作者 Andrew Gibiansky 之前在百度硅谷 AI 实验室工作,后来联合创办了语音合成公司 Voicery(不过悲剧地发现这家公司今年 10 月份已经关了)。基于 Andrew Gibiansky 的成果,Uber 开源了目前公认的 Ring Allreduce 标准框架 Horovod。
Introducing TensorFlow Recommenders
推荐系统是一直都是机器学习一个重要的应用领域,如果你不了解什么是推荐系统可以看我之前写的一篇简介。使用 TensorFlow 可以很方便地训练一个推荐系统模型,不管是召回模型还是排序模型。现在 TensorFlow 官方将这个流程进一步简化,推出了 TensorFlow Recommenders(TFRS)库,旨在让训练、评估、serving 推荐系统模型更加容易,并且融合一些 Google 自己的经验,对于初学者来说会是一个好的入门指南。
]]>